
使用 Kafka 实现分布式消息传递系统
使用 Kafka 实现分布式消息传递系统
第一章 Apache Kafka 入门
为什么是 Kafka
成为传统消息代理的好选择的原因
- 多个生产者
- Kafka 能够无缝地处理多个生产者,无论这些客户使用的是多个主题还是同一个主题
- 多个消费者
- Kafka是为多个用户设计的,可以在不相互干扰的情况下读取任何单一的消息流。
- 及预测盘的 Rentention (持久化)
- 消息将提交到磁盘,并将使用可配置的保留规则进行存储:按时间或者容量配额
- 可以根据每个主题选择这些选项,从而允许不同的消息流具有不同的保留量,具体取决于消费者的需要
- 可伸缩
- Kafka 灵活的可伸缩性使处理任何数量的数据变得容易。用户可以从一个代理开始作为概念证明,扩展到由三个代理组成的小型开发集群,然后随着数据规模的扩大,由数十个甚至数百个代理组成的更大集群投入生产。当不再需要大集群时,可以动态缩容,不影响正在处理的消息
- 高性能
- 生产者、消费者和代理都可以被扩展,以轻松地处理非常大的消息流
Kafka 用例
下面是一些 Kafka 的流行用例
消息传递
- 消息代理用于将数据处理与数据生产者分离
网站活动跟踪
- Kafka最初的用例是能够将用户活动跟踪管道重建为一组实时发布订阅源
- 这意味着站点活动(页面视图、搜索或用户可能采取的其他操作)将发布到中心主题,每个活动类型有一个主题
Metrics (监控指标)
- 应用程序定期向Kafka主题发布 Metrics
日志聚合
- 使用 Kafka 可以将日志或事件数据抽象为消息流,从而消除对文件细节的依赖
流式处理
Kafka在多个阶段收集数据进行处理——例如,从Topic消耗的原始数据被丰富或转换为新的 Kafka Topic 以供进一步使用。因此,这种处理也称为流处理
Kafka 组件
- 消息处理和批处理
- 就Kafka而言,消息只是一个字节数组,因此其中包含的数据对Kafka来说没有特定的格式或含义
- 批处理只是消息的集合,所有这些消息都是针对同一主题和分区生成的
- 模式
- 根据应用程序的个别需要,消息模式有许多可用的选项。简单化的系统,如JavaScript对象表示法(JSON)和可扩展标记语言(XML),易于使用和可读
- 在Kafka中,一致的数据格式是很重要的,因为它允许消息的读写分离
- 主题和分区
- 主题还被分解为多个分区。回到“提交日志”描述,分区是单个日志
- 生产者和消费者
- 生产者创造新的信息。在其他发布/订阅系统中,这些可能被称为发布者或写入者
- 消费者阅读信息。在其他发布/订阅系统中,这些客户端可以称为订阅服务器或读卡器
- 消费者可以横向扩展以使用包含大量消息的主题。此外,如果单个使用者失败,组的其余成员将重新平衡正在使用的分区,以接管丢失的成员
- 代理和集群
- 单个 Kafka 服务器称为代理。代理接收来自生产者的消息,为其分配偏移量,并将消息提交到磁盘上的存储器中
- Kafka 代理是设计成集群的一部分
- 控制器负责管理操作,包括为代理分配分区和监视代理故障。控制器 Broker 从集群所有的 Broker 中选举出来
- 一个分区由集群中的一个代理拥有,这个代理称为分区的 Leader
- Apache Kafka 的一个关键功能是保留功能,它是一段时间内消息的持久存储
- 达到这些限制后,消息将过期并删除,以便保留配置是随时可用的最小数据量
第二章 安装 Kafka
安装 Kafka Broker
校验 Java 安装
1 | java -version |
1 | which java |
1 | export | grep "java" |
启动 Zookeeper
1 | sudo ./zkServer.sh start |
1 | sudo jps -l |
启动 Kafka 并创建 Topic
1 | kafka-server-start.sh -daemon server.properties # 启动 Kafka |
1 | kafka-topic.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic mytopic # 创建 topic |
先生成消息, 再消费消息
1 | kafka-console-producer.sh --broker-list localhost:9092 --topic mytopic # 生成消息 |
1 | kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytopic --from-beginning # 消费消息 |
Kafka Topic toolkit
创建 topic
1 | kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test |
查看 topic 配置信息
1 | kafka-topics-zookeeper localhost:2181 --describe --topic test |
查看 topic 列表
1 | kafka-topics-zookeeper localhost:2181 --describe --topic test |
改变 topic
1 | kafka-topics --zookeeper localhost:2181 --alter --topic test --config message.max.bytes=12800 # 改变 topic 配置 |
1 | kafka-topics --zookeeper localhost:2181 --alter --topic test --partitions 2 # 添加分区 |
第三章 Kafka 生产者
Kafka 生产者概况
需要把消息写入 Kafka 的目的
- 记录用户活动以便审查或分析
- 记录指标(metrics)
- 储存日志消息
- 记录智能设备信息
- 与其他应用异步通信( Communicating Asynchronously )
- 写入数据库前缓存信息
在应用中使用 Kafka 生产者前需要确定
- 消息的重要程度
- 是否接受消息丢失
- 是否接受重复发送消息(Duplicate Messages)
- 消息的延迟( Latency )程度
Java 生产者 API
Kafka 生产者类 (KafkaProducer)
- 该类可在
org.apache.kafka.clients.producer包获得。 - 这是通用类,我们需要指定参数的类型; K 和 V 分别指分区的键(partition key)和消息的值(message value)
- 该类可在
生产者记录类 (ProducerRecord)
- 即需要发送到 Kafka 的一个键/值对(key/value pair )。由主题名称(topic name),可选的分区号(partition number)以及可选的键值对组成
生产者配置类 (ProducerConfig)
- 该类可在
org.apache.kafka.clients.producer获得 - 它有助于设置 Kafka 生产者的配置
- 该类可在
同步发送消息
- 消息已发送,生产者等待对第一条消息的确认响应以发送第二条消息
1 | ProducerRecord<String, String> recode = new ProducerRecord<>("Course", "Kafka", "China"); |
异步发送消息
- 我们不需等待到收到响应确认后再发送下一条消息
1 | private class NIITProducerCallback implements Callback { // 关键行 1 |
配置 Kafka 生产者
- 使用属性创建生产者配置对象
- 使用我们刚刚提供的设置创建生产者对象
- 创建要推送到 Kafka 主题的消息
- 调用
send()方法 - 发送消息后, 调用
close方法
1 | // 使用属性创建生产者配置对象 |
第四章 Kafka 消费者
Kafka 消费者简介
消费者的使用场景
- 进行实时或接近实时分析的应用程序
- 使用NoSQL数据存储的应用程序
- 大数据数据仓库解决方案
- 后端服务的业务处理
- Hadoop 系统中的消费者
- 其他基于订阅者( subscriber-based )的解决方案
交付语义
提交偏移量就像读者在阅读书籍或小说时使用的书签。 在Kafka中,使用了以下三种交付语义( delivery semantics )
- 最多一次 (AMOS: At Most Once Semantic) : 偏移量在消费者收到消息后立即提交
- 至少一次 (ALOS: At Least Once Semantic) : 在处理完消息后提交偏移量
- 恰好一次 (EOS: Exactly Once Semantic) : 使用 Kafka Streams API 可以实现从 Kafka 到 Kafka 工作流程的偏移量
| 最多一次 | 至少一次 | 恰好一次 |
|---|---|---|
| 信息只提交一次 | 信息至少提交一次 每次提交都会处理 |
信心至少提交一次 只处理一次 |
| 可以接收, 也可以不接收 | 保证会接收 | 保证会接收 |
| 无重复值 | 有重复值 | 无重复值 |
| 可能会丢失数据 | 不会丢失数据 | 不会丢失数据 |
消费者组和分区重平衡
重平衡发生在以下事件
扩大消费者组规模 (Scaling Up)
将新消费者添加到消费者组。 新消费者开始使用先前由另一个消费者使用的分区中的消息
缩减消费者组规模 (Scaling Down)
将消费者从消费者组中删除。 另一个消费者开始使用已删除分区中的消息
主题增加分区
应用程序崩溃
消费者客户端关闭
存活的消费者开始使用先前由另一个消费者使用的分区中的消息
由于消费者客户端崩溃导致组协调器( group coordinator)将某位消费者视为DEAD时,也可能发生在消费者忙于长时间运行处理时。意味着在此期间,消费者没有在配置的会话间隔内向组协调器发送任何心跳信号
有消费者订阅任何主题
如果您订阅尚未创建的主题,则创建主题后将触发重新平衡。 如果您订阅的主题被删除,也会触发重发重平衡
Java 消费者 API – 高级 API
实现了:
每个主体中每个分区的偏移量管理
Kafka 服务器故障转移(failover,broker list 添加多个 broker 主机地址)
分区和消费者改变导致的负载重平衡(load balancing)
整洁统一的 API
高级消费者结合了旧版本(Low Level)消费者客户端的 “Simple” 和原本新版本(High Level)消费者客户端的功能
减少依赖
新消费者使用纯 Java 编写(旧消费者使用 Scala 语言编写)
安全性更好
高级 API
KafkaConsumer
Kafka 消费者客户端,用来消费 Kafka 集群中的消息
ConsumerRecord
从 Kafka 接收的消息的 键/值对。 还包括主题名称,接收记录的分区号,所在 Kafka 分区中记录的偏移量,以及由相应生产者标记的消息的时间戳
ConsumerRecords
它是消费者记录的容器。 为了保留特定主题的每个分区的消费者记录列表,我们使用此API
KafkaConfig
可帮助设置配置属性
ConsumerConnector
负责消费者与 ZooKeeper 交互
KafkaStreams
通过 KafkaStreams API,Kafka 客户端可以对来自一个或多个主题的输入执行连续计算,并将输出发送到零个,一个或多个主题
TopicPartition
这有助于从特定主题和分区中检索消息
要创建 Kafka 消费者, 需要先设置属性
1 | KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); |
订阅主题
1 | // 单一主题 |
poll 轮询处理协调、分区重平衡、心跳 (heartbeats) 和数据提取的所有详细信息
1 | while (true) { |
配置 Kafka 消费者
- 创建消费者属性
- 创建消费者
1 | // 创建消费者属性 |
读消息
1 | // 1. 为消费者订阅特定消息 |
Java 消费者 API – 低级 API
不常用或仅在调试时使用 (在较新的版本中已取消)
实现了:
- 更好地控制Kafka 消息的使用
- 多次读取相同的消息
- 只消费主题的部分分区
- 手动管理事务确保消息只处理一次且仅处理一次 (Exactly Once primitive)
- 更灵活的控制,但以复杂性为代价
- 偏移量不再透明
- 缓存代理自动故障转移需要手动处理
- 添加消费者,分区和 Broker 之后需要您自己进行负载平衡
低级 API
简单消费者(kafka.javaapi.consumer.SimpleConsumer)
有助于连接到lead broker,进而获取主题中的消息,并提供了一些获取主题元数据和偏移量列表的方法
发起拉取请求 (kafka.api.FetchRequest)
偏移量请求 (kafka.javaapi.OffsetRequest)
偏移量拉取请求 (kafka.javaapi.OffsetFetchRequest)
偏移量提交请求 (kafka.javaapi.OffsetCommitRequest)
主题元数据请求 (kafka.javaapi.TopicMetadataRequest)
第五章 Kafka 监控和管理
5.1 主题操作
- Kafka 提供了一个命令行实用程序
kafka-topics.sh来操作 Kafka 服务器上的主题。在做操作之前,需要先启动并运行 kafka 集群
创建主题
- 使用 kafka-topics.sh 工具创建一个名为 my-topic 的主题,它只有 1 个分区和 1 个副本
1 | bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my-topic --replication-factor 1 --partitions 1 |
1 | # 上面指令的参数 |
获取主题信息
- 为了获取特定主题的详细信息, 可以执行下面的命令
1 | bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic mytopic |
1 | # 关于输出的解释 |
为主题添加分区
- 可以为现有的 Kafka 主题添加分区
--alter选项可以改变主题分区的数量, 副本数量以及配置信息- 为上一步中创建的主题添加一个分区
1 | kafka-topics.sh --bootstrap-server localhost:2181 --alter --topic mytopic --partitions 2 |
删除主题
1 | bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic my-topic |
列出集群汇总所有主题
- 获得一个 Kafka 集群汇总某台服务器上所有可用的主题列表
1 | bin/kafka-topics.sh --zookeeper localhost:2181 --list |
5.2 消费者操作
- 使用
kafka-consumer-groups.sh工具,我们可以列出、描述或删除消费者组。消费者组可以被手动删除,也可以在该组最后一次提交的偏移量到期时被自动删除。手动删除仅在组中没有任何活动成员时有效
列出消费者组
1 | bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list |
1 | # 输出 |
描述消费者组
- 下面语句会列出指定消费者组正在使用的所有主题, 以及每个主题分区的偏移量
1 | bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group |
1 | # 输出 |
删除消费者组
--delete选项可以删除一个或多个消费者组
1 | bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group my-group --group my-other-group |
1 | # 输出 |
偏移量管理 – 删除操作
- 使用
--delete-offsets删除消费者组偏移量, 此方法支持一个消费者组和一个或多个主题
1 | kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete-offests --group my-group --topic my-topic-1 --topic my-topic-2 |
1 | # 输出 |
偏移量管理 – 重置操作
- 使用
--reset-offsets选项重置消费者组的偏移量, 此选项一次支持一个消费者组 - 并且需要定义以下范围:
--all-topic或--topic - 必须选择上面两个作用域, 除非使用
--from-file以文件的方式导入
1 | bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --reset-offsets --gropu consumergroup1 --topic topic1 --to-latest |
1 | # 输出 |
1 | # 上面指令的参数 |
5.3 动态配置修改
- 动态配置修改意味着在修改配置后我们不需要重新启动 broker 来使其生效
- 这个新特性包含在
kafka-configs.sh的命令行工具脚本中, 使用了这个工具配置参数, 新的更改会永久存储在 zookeeper 集群中
覆盖主题默认配置
- 有许多应用于主题的配置,可以针对单个主题更改这些配置以适应集群中的不同用例
- 大多数配置都在代理配置中指定了缺省值,除非设置配置覆盖,否则将应用该缺省值
1 | # 指令格式 |
1 | # 将 my-topic 主题的留存时间设置为 1 小时, 即 3600000ms |
1 | # 输出 |
1 | # kafka 主题中的部分有效配置 |
覆盖客户端默认配置
- Kafka 客户端唯一可以覆盖的配置是生产者和消费者的配额,即允许具有指定客户端 ID 的所有客户端在每个 broker 上每秒生产或者消费的字节数
1 | # 指令格式 |
1 | # kafka 客户端的有效配置 |
显示覆盖的配置
- 可以使用命令行工具
kafka-configs.sh来检查主题或客户机的特定配置。显示覆盖的配置需要使用--describe选项
1 | # 显示名为 my-topic 的主题的所有覆盖过的配置 |
1 | # 输出 |
删除覆盖的配置
- 完全删除动态配置,将导致集群配置恢复到默认值. 要,使用
--alter命令以及--delete-config命令删除配置覆盖
1 | # 删除名为 my-topic 的主题的覆盖后的 retention.ms 配置, 即将它恢复默认值 |
1 | # 输出 |
第六章 流处理
6.1 什么是流处理
流处理 Stream Processing
- 数据流( data stream,也称为事件流 event stream 或流数据 streaming data )是无界数据集(Unbounded Dataset)抽象的表示
- 流处理 Stream processing 是指对一个或多个事件流的持续处理
- 事件流模型除了无边界之外,还有以下性质
- 事件流的处理是有序的 Event streams are ordered (上游处理完接着下游处理)
- 发射到事件流中的数据记录是不可变的 Immutable data records(事件不可篡改)
- 事件流是可重播的 Event streams are replayable(错误重试,重新分析或者审计)
Kafka Stream 的特点
Kafka Stream 提供了对存储于 Kafka 内的数据进行流式处理和分析的功能
- Kafka Stream 提供了一个非常简单而轻量的 Library,它可以非常方便地嵌入任意 Java 应用中,也可以任意方式打包和部署
- 除了 Kafka 外,无任何外部依赖
- 充分利用 Kafka 分区机制实现水平扩展和顺序性保证
- 通过可容错的 state store 实现高效的状态操作(如 windowed join 和 aggregation)
- 支持恰好一次 (EOS: Exactly Once Semantic) 处理语义
- 提供记录级的处理能力,从而实现毫秒级的低延迟
- 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语 Processor(类似于Storm的spout和bolt),以及高层抽象的 DSL(类似于 Spark 的 map/group/reduce)
6.2 流处理概念
- 在流处理过程中,流处理,通常接收数据、对数据执行一些转换、聚合、扩充等的数据的任何类型的数据处理
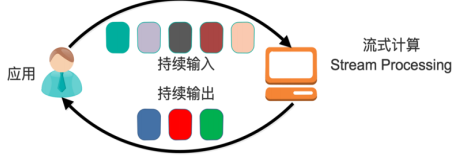
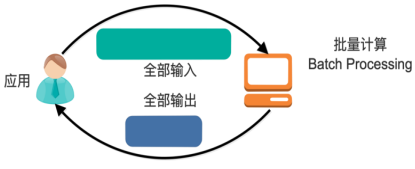
- 一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算
流处理关键概念 – Time (时间)
从 Kafka 0.10 版本开始,生产者自动把时间戳信息追加到发送的消息中
Kafka消息目前支持的时间戳类型有两种: CreateTime 和 LogAppendTime 前者表示 producer 创建这条消息的时间;后者表示 broker 接收到这条消息的时间 (严格来说,是 leader broker 将这条消息写入到 log 的时间)
引入时间戳主要解决3个问题:
- 日志保存 (log retention) 策略
- 日志切分 (log rolling) 策略
- 流式处理 (Kafka streaming):流式处理中需要用到消息的时间戳,在流处理的上下文中,有一个共同的时间概念是至关重要的,因为大多数流应用程序在时间窗口上执行操作。例如,我们的 stream 应用程序可能会计算股票价格的5分钟移动平均值。下面是流式处理经常遇到的时间戳类型:
- Event Time:跟踪的事件发生和记录创建的时间,通常是流式处理最常用的时间
- LogAppend Time:事件到达 Kafka 代理并存储在那里的时间,受网络影响,可能0点前的数据 0 点后才到达 Broker
- Processing Time:应用程序最终消费事件执行某些处理的时间,无法保证实时,不可靠。
如何使用时间戳 ?
Kafka broker config 提供了一个参数:
log.message.timestamp.type来统一指定集群中的所有 topic 使用哪种时间戳类型。用户也可以为单个 topic 设置不同的时间戳类型,具体做法是创建 topic 时覆盖掉全局配置:1
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test --partitions 1 --replication-factor 1 --config message.timestamp.type=LogAppendTime
producer 在创建 ProducerRecord 时可以指定时间戳
1
ProducerRecord record = new ProducerRecord<String, Stirng>("my-topic", null, System.currentTimeMillis(), "key", "value");
流处理的关键概念 – State (状态)
流式处理中,部分操作是无状态的,例如过滤操作。而部分操作是有状态的,需要记录中间状态,如 Window 操作和聚合计算。存储中间状态的方式有可以是一个持久化的 Key-Value 存储,也可以是内存中的 HashMap,或者是数据库。而 Kafka 提供了基于 Topic 的状态存储
本地或内部状态
优势在于速度快。缺点是可用的容量有限。另外将流处理的中间状态保存在内存中是不可靠的,因为当流处理应用程序停止时,状态将丢失,从而改变结果
外部状态
在外部数据存储中维护状态,通常是像 Cassandra,HBase 这样的 NoSQL 系统。外部存储中维护状态的优点是它几乎有无限的容量(可扩展),并且可以从应用程序的多个实例甚至不同的应用程序来远程访问它。缺点是会增加延迟和系统复杂性。大多数流处理的应用程序尽量减少与外部存储通信来控制延迟开销
流处理的关键概念 – Stream Table Duality (Stream 和 Table 之间的二元性)
Kafka Streaming 中 流表二元性
- 流是导致更改的一串不可变的有序事件
- 表是记录的集合,像关系数据库一样,记录由其主键标识,并包含一组属性,可以更改并记录最新状态
- 为了将流转换为表,我们需要应用流包含的所有更改
- 这也称为实现流(materializing the stream)
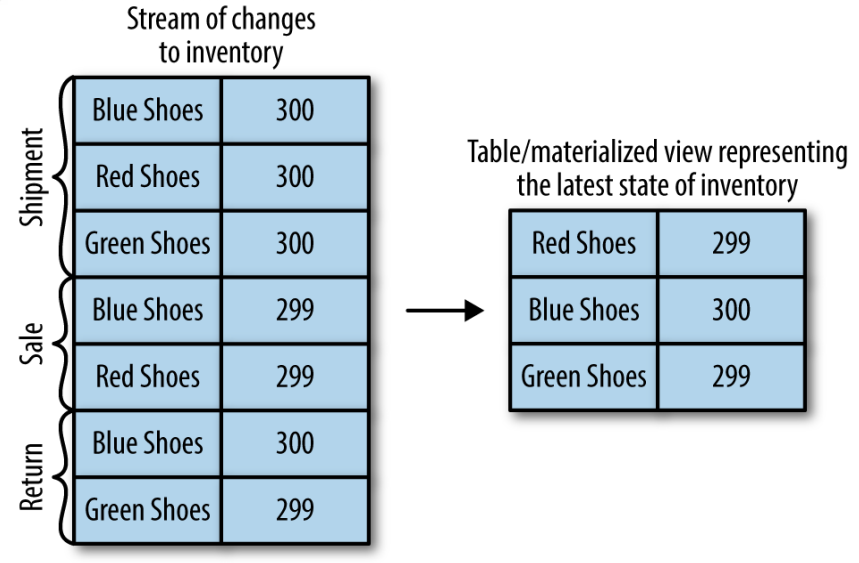
- 举例说明:鞋店的零售活动的事件流表示:
- “货物到达时,有红、蓝、绿三种颜色的鞋子各300双”
- “出售蓝色鞋子以及红色鞋子各一双”
- “之前售出的1双蓝鞋子遭到客户退货”
- “出售绿色鞋子1双”
- 鞋店库存的状态可用表来表示
- 每当事件到来,更新表
- 表中存储的是最新状态
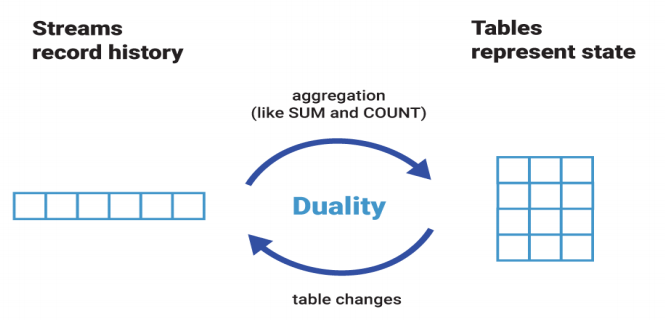
流和表之间存在着密切的关系。 我们称之为流表二元性。 这意味着:
- 我们可以通过使用诸如 COUNT() 或 SUM() 等操作将流聚合为表。 在我们的国际象棋类比中,我们可以通过重放所有记录的动作 (流) 来重建棋盘的最新状态 (表)
- 相反,也可以通过对比棋盘的前后状态,识别发生了何种事件,进而构成完整的事件流,不过这样转换的效率会很差
下面是使用 COUNT() 将流聚合成表的示例。 出于说明性的原因,没有显示事件时间戳。
随着新事件到达流中,该表不断更新。在此示例中,具有 Key= UserID 和 Value=Location 的事件流被聚合到一个不断更新的表中,该表跟踪每个 Key= UserName

我们可以放大 COUNT() 示例,以显示表的 (输出) 更改流。 更改流可以用来实时地对表更改做出反应,例如发出警报。或者例如当出现机器故障或集群扩(缩)容时,利用更改流将表从机器 A 迁移到机器 B

流处理的关键概念 – Window (时间窗口)
6.3 流处理设计模式
6.4 Kafka 流: 架构概述
6.5 流处理用例
 wechat
wechat alipay
alipay




