
Flume使用指南
Flume使用指南
一、安装 Flume
首先检查机器是否联网
8.8.8.8是Google提供的公共 DNS 服务器的IP地址。ping 命令是用来测试网络通信的,它通过向目标IP地址发送数据包并等待响应,来检查是否能够成功地与该地址进行通信。通过向Google提供的公共DNS服务器发送数据包并等待响应,可以检查本地主机是否能够成功地连接到互联网上的其他计算机。因为Google的公共 DNS 服务器在全球多个位置提供服务,并且稳定可靠,所以它成为了Linux用户常用的网络测试地址之一。
当用户发现自己的电脑无法上网时,可以使用
ping 8.8.8.8命令来检查是否能够与 Google 的DNS服务器进行通信。如果能够成功连接,那么问题可能出现在其他地方,如果连接失败,则意味着可能存在网络连接问题,需要进一步检查和解决。
1 | $ ping 8.8.8.8 |
检查 nc(netcat) 的版本
netcat(也称为nc)是一种网络工具,它是一个非常强大的用于创建 TCP/IP 连接的命令行工具。netcat的功能十分强大,可以用于端口扫描、文件传输、调试协议等多种场景。通过
netcat可以进行以下操作:
- 在主机之间传输数据,可以作为 client(客户端)或 server(服务器)。
- 在不打开 FTP、SSH、Telnet 等服务的情况下,创建服务器程序,监听端口并处理连接请求。
- 进行端口扫描和服务探测,可测试端口是否打开,并查看被连接服务的协议版本。
- 通过网络发送文件或数据,如将文件拷贝到目标主机、进行数据备份等。
- 调试网络协议,可以手动输入数据包并观察响应信息来调试各种协议的通信。
netcat是一个非常灵活的工具,它可以作为一个网络的 Swiss Army Knife,可以被用于多种不同的目的。但同时,由于其强大的功能和灵活的使用方式,也可能被用于网络攻击和安全测试,因此在使用时需要谨慎。
1 | $ nc -version |
如果你的虚拟机没有 nc ,使用以下指令来安装
1 | $ yum install nc |
GUI 用户打开虚拟机中的浏览器,然后复制链接点击下载 https://archive.apache.org/dist/flume/1.9.0/
命令行用户在安装目录下执行以下指令(需要安装 wget 工具)
1 | $ wget https://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz |
没有 wget 工具的执行以下指令进行安装
1 | $ yum install wget |
解压安装包
1 | $ tar -xvf apache-flume-1.9.0-bin.tar.gz |
将解压之后的文件夹进行重命名为 flume
1 | $ mv apache-flume-1.9.0-bin flume |
将重命名之后的文件夹移动到 /training 文件夹下(大数据所有组件都在这里)
1 | $ mv flume /training/ |
修改配置文件
1 | vi ~/.bash_profile |
将下面两行加入配置文件
export FLUME_HOME=/training/flume/
export PATH=$PATH:$FLUME_HOME/bin
重新导入资源
1 | $ source ~/.bash_profile |
查看 flume 版本
1 | $ flume-ng version |
查看 JAVA_HOME
1 | $ $JAVA_HOME |
将 flume-env.sh.template 文件重命名为 flume-env.sh
1 | $ mv /training/flume/conf/flume-env.sh.template flume-env.sh |
修改 flume-env.sh 文件
1 | $ vi /training/flume/conf/flume-env.sh |
将 flume-env.sh 文件中的 JAVA_HOME 修改位自己的 jdk 路径
1 | export JAVA_HOME=/training/jdk1.8.0_301 |
再次查看 flume 版本
1 | $ flume-ng version |

二、什么是 Flume
Flume是一个高可靠性、高可用性、分布式、可定制化的海量日志采集、聚合和传输的系统工具。
Flume 是 Apache 的一个开源项目,是一个分布式日志收集系统,以流水线的方式收集、聚合日志。它具有高可扩展性和高可靠性,可以在不停机的情况下进行在线扩容和日志收集。
Flume 支持多种数据源,例如 Avro、Netcat、JMS、Exec、Thrift 等,也支持多种数据目的地,例如 HDFS、HBase、Solr、Elasticsearch 等。
Flume 的核心工作单元是 Agent,它由三个主要组件组成:Source、Channel 和 Sink,分别表示数据来源、数据缓存和数据目的地。
Flume 有许多不同的使用场景,例如日志收集、数据摄取、事件处理等,广泛应用于 Web 应用程序、大数据、云计算等领域。
没有 Hadoop 我们也可以运行 Flume
从不同的数据源手机数据,然后传输到中心化储存的系统中
不依赖于任何操作系统,可以运行在任何设备
Flume Event
Flume Event 是 Apache Flume 中的一个概念,代表了一个在 Flume Agent 中传输的数据单元。一个 Flume Event 包含了一个数据载体和多个可选的头部信息(header)。其中,数据载体是必须的,而头部信息是可选的。
Flume Event 的数据载体是一个字节数组,在传输过程中可以被多个
Source和Sink共享使用。Flume Event 的头部信息是一组键值对,通过这些头部信息可以对数据进行标记和描述,例如可以包含数据的来源、时间戳、数据类型、序列号等信息。在 Flume Agent 中,多个
Source可以向一个Channel发送Flume Event,多个Sink可以从一个Channel中获取 Flume Event。在传输过程中,每个 Flume Event 可以通过拦截器(interceptor)进行处理,例如可以对数据进行清洗、格式化、过滤等操作,从而满足不同的业务需求。需要注意的是,在 Flume Agent 中,一个 Flume Event 的传输是基于异步的,即在发送和接收 Flume Event 的过程中,不需要等待对方的响应。这种设计可以确保高效地传输大量的日志和事件数据。同时,Flume Event 的传输还可以进行批量处理,从而进一步提高传输效率。
Flume 用来传送数据的最小单位,一个 event 就是一个数据的单位,event 就是数据,许多数据流的集合
Flume Agent
Flume Agent 是 Apache Flume 中的一个概念,代表了一个在单个 JVM 进程中运行的 Flume 实例。可以将 Flume Agent 看作是一个数据传输管道,通过各种
Source和Sink连接起来,从而实现数据的采集、传输、处理等功能。在 Flume Agent 中,每个
Source和Sink都是一个独立的组件。Source用于采集数据,可以从各种数据源中获取数据,例如从日志文件、网络流、消息队列、Twitter 等等中获取数据。Sink用于输出数据,可以将获取到的数据输出到各种存储或处理目的地,例如输出到 HDFS、HBase、MySQL、Kafka、Elasticsearch 等等。除了
Source和Sink组件,Flume Agent 中还有一个Channel组件。Channel是连接Source和Sink的缓冲区,用于暂存从Source中获取到的数据,等待Sink进行输出。Flume Agent 中可以配置多个Source和多个Sink,它们通过Channel进行连接,从而实现数据的传输和处理。Flume Agent 的配置文件通过指定各个组件的名称、类型、属性等来实现对 Agent 的定义。Flume Agent 配置文件的结构与 XML 文件类似,由
<agent>标签组成,其中包含了多个<source>、<channel>、<sink>标签,每个标签都包含了对应组件的相关配置信息。在配置好 Flume Agent 后,可以通过启动 Flume Agent 进程来启动整个数据传输管道,从而实现数据的采集、传输、处理等功能。
Flume Agent(Flume代理)是 Flume 中的核心概念之一,代表一个 Flume 进程实例,其中包含
Source、Channel和Sink三个组件。Flume Agent 用于采集、聚合和传输日志和数据,可运行于单个节点或多个节点的集群中。每个 Flume Agent 进程都可以独立工作,同时也可以和其他 Flume Agent 进程协同工作,以实现更高的可靠性和扩展性。Flume Agent 包含以下三个核心组件:
Source(数据源):负责从数据源(例如文件、日志、数据流、消息队列等)收集数据,并将数据传递到Channel。Channel(数据缓存):负责存储Source收集到的数据,以便Sink进一步处理。Channel可以是内存缓存、文件系统缓存、Kafka 等第三方缓存系统。Sink(数据目的地):负责将数据从Channel读取并将其传输到目标系统,例如 HDFS、HBase、Elasticsearch、Solr 等。Flume Agent 可以根据需要自定义配置,如定义多个 Source
、Channel和Sink`,也可以将多个 Agent 配置成一个 Agent 组,以实现更高效的数据采集和传输。
web server 网路服务器,不停产生日志文件,是一个数据源
Flume agent 的任务是将日志文件传输到HDFS中
source 将日志数据从网络服务器传输到 channel 中,拉取数据
channel 将存储数据并传输到 sink
sink 消费从 channel 传来的数据并将他们传输到 HDFS,推送数据
-put 每次只能传输一个文件(从本地到HDFS),这就是第一个限制
flume 可以实时与 hadoop 链接,这样就不用来一个数据执行一次 -put命令了
flume 可以发送大量 实时数据,可以管理数据流
channel会存储数据,直到sink将所有数据都存储到HDFS 中,channel才会把这些数据删除
如果hdfs接收的速度小于webserver发送的速度,channel就会把剩下的数据存储起来,直到sink将其存储到hdfs
channel就像水阀
临时保存
一种是临时保存在内存上,另一种是保存在一个文件上
内存会比硬盘更快,
complex data flow
“复杂数据流”是指在数据处理系统中的一种数据流,它包含一系列复杂的计算和处理过程,用于处理和转换复杂的数据结构。这种处理方式通常需要使用一些先进的数据处理技术和算法,如机器学习、图像处理、自然语言处理等。
复杂数据流通常涉及到多个数据处理阶段,每个阶段都需要处理原始数据并输出处理结果。每个阶段的处理方式和输出结果通常会影响到下一个阶段的处理方式和输出结果。因此,在设计和实现复杂数据流时需要考虑到数据处理阶段之间的依赖关系和数据流的整个工作流程。
复杂数据流可以应用于各种领域,例如金融、医疗、电商、物流等等,用于解决各种数据处理和决策方面的问题。然而,设计和实现复杂数据流也是具有挑战性的,需要考虑到数据的质量、效率、可靠性和安全性等因素。因此,许多现代数据处理系统提供了各种复杂数据处理和分析的工具和框架,以帮助企业处理和分析大量数据,并从中获得更多价值。
Flume Avro 是 Flume 中用于实现数据流的一种机制。Avro 是一种数据序列化格式,它具有良好的可扩展性和高效性能,使得 Flume Avro 可以非常高效地传输大量数据。Flume Avro 可以通过 Avro Source 和 Avro Sink 实现数据的传输,使用 Avro 的优点是可以减少数据传输时所需的带宽和网络延迟。
Avro Source 是 Flume 中的一种 Source 类型,用于接收 Avro 格式的数据。它可以从任何支持 Avro 协议和数据类型的源系统中接收数据,并将其传输到 Flume 的 Channel 组件中,以便后续处理。 Avro Sink 是 Flume 中的一种 Sink 类型,用于将数据传输到支持 Avro 格式的目的地系统。它可以从 Flume 的 Channel 组件中获取数据,并将其传输到目标系统,例如 Avro RPC 服务、HDFS、HBase、Elasticsearch 等。
使用 Flume Avro 的好处是,它可以支持面向数据的实时流处理,同时也可以有效地降低数据传输时所需的带宽和延迟。在 Flume Avro 中,数据是以二进制格式传输的,数据包括数据类型和数据值,可以快速地进行序列化、反序列化和传输。同时,使用 Avro 的模式定义语言,可以定义和更新数据模式,从而支持数据的演进。这种灵活的模式定义方式使得 Flume Avro 可以支持向后兼容和向前兼容,使得数据流处理更加容易和灵活。
当我们使用复杂数据流的时候,我们需要使用avro
。在计算机领域中,replicating 通常指复制数据或实现数据的冗余备份,以增加数据的可靠性和可用性。通过复制数据或备份数据,可以保证数据不会因为单点故障而丢失,同时也可以提高数据的读取速度和吞吐量。Replication 在数据库、分布式系统以及数据中心等领域中被广泛应用。
netcat是一个数据生成器
在 Flume 中,Replicating 是一种 Channel 类型,用于在多个 Sink 之间复制消息。当使用 Replicating Channel 时,Flume 会将每个事件广播到多个 Sink,从而提高了消息的可靠性和可用性。Replicating Channel 相对于其他 Channel 类型的优点是,可以同时将消息发送到多个 Sink,从而减少了单点故障的风险,并且可以提供更好的消息传递效率。
在使用 Replicating Channel 时,每个 Sink 都会接收到相同的消息,并且处理消息的方式也相同。这种方式适用于许多场景,例如在多个数据中心之间复制消息,或者在多个目的地系统之间分发消息。使用 Replicating Channel 可以确保消息的一致性,并提高消息的投递成功率。
需要注意的是,在使用 Replicating Channel 时,由于每个事件都要广播到多个 Sink,因此会增加网络带宽的使用量。同时,如果 Sink 数量很多,也会增加 Flume Agent 的负载和延迟。因此,在使用 Replicating Channel 时需要根据具体情况权衡利弊,选择合适的 Channel 类型和 Sink 数量。
multiplexing可以分发数据到不同的hdfs
Flume 可以传输非结构化数据
FLumeData = filePrefix
是个默认名字后缀
改名字只是更改前缀
三、Flume 的操作
使用另一台机器作为数据源
设置agent name设置source name设置channel name设置sink name
1
agentname.source = sourcename //我们可以使用任何名字来命名
定义source 的属性
1
2
3
4agentname.sources.sourcename.type = netcat; //有专门的几个词,不能随意
agentname.sources.sourcename.bind = localhost; //ip地址
agentname.sources.sourcename.port = portnumber(1-65000);
//我们不能定义 channel的属性
1
agentname.channel.channelname.type = memory;//有专门的几个词,不能随意
定义sink 的属性
1
agentnamename.sink.sinkname.type = logger //是hdfs的话就写和hdfs,logger是终端(terminal)
在channel的帮助下链接source和sink
1 | # names of agent,source,channel,sink |
1 | # names of agent,source,channel,sink |
启动 Flume
1 | $ flume-ng agent -n agentname -f filename |
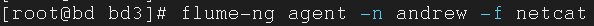
1 | $ flume-ng agent -n agentname -f filename |

运行指令后出现端口号表示执行成功
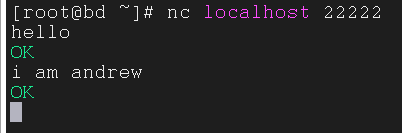
我们启动另一个窗口来当做另一台机器来链接 Flume
输入指令来链接 Flume
1 | $ nc localhost 22222 |
1 | $ nc localhost 22222 |

使用 Windows 作为数据源
现在我们用Windows来当做source源来运行flume
在 Linux 中写入配置文件,带不带 .config 都可以
1 | andrew.sources=win_source |
1 | andrew.sources=win_source |
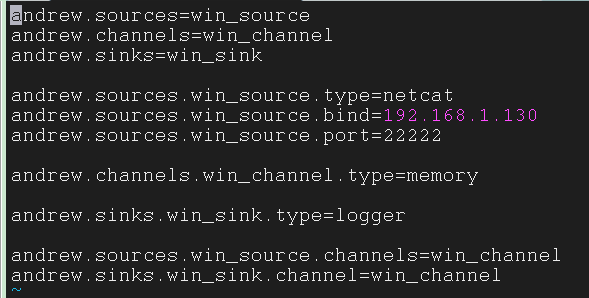
启动 flume
1 | $ flume-ng agent -n andrew -f win |
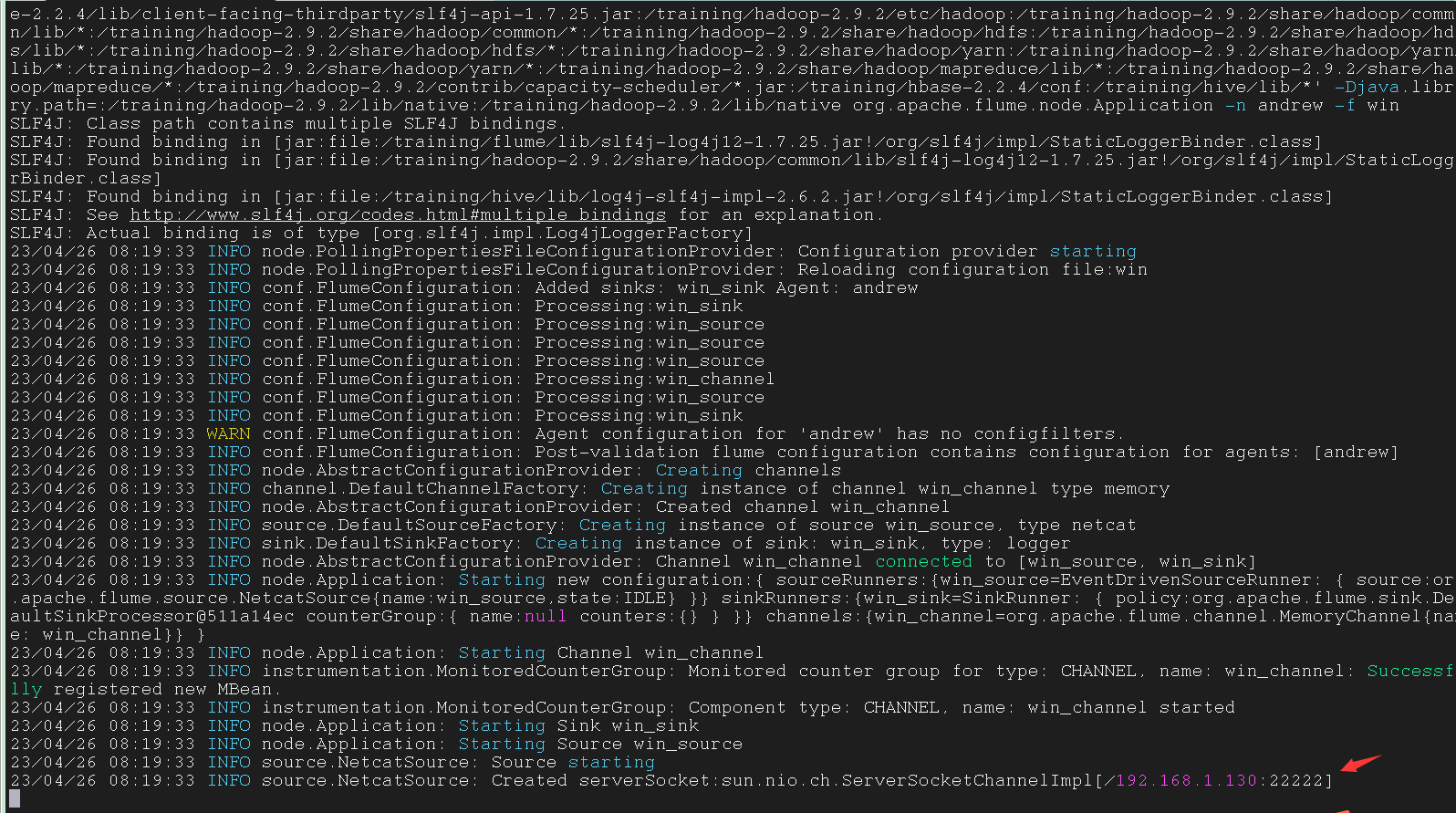
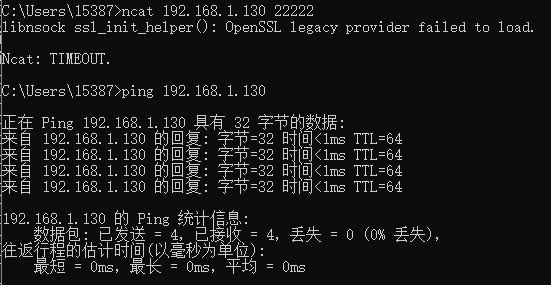
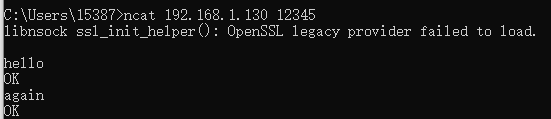
在 Windows 中断中输入指令,连接虚拟机
1 | $ ncat 192.168.1.130 22222 |


Flume 与防火墙
这一部分是以后工作中可能需要用到的
注意一下指定都需要使用
sudo执行
查看防火墙状态
1 | $ sudo systemctl status firewalld |
启动防火墙
1 | $ sudo systemctl start firewalld |
启动防火墙之后我们饿就不能接收这个 IP 地址的消息了
防火墙打开,端口就被封闭住了
查看端口是否开放(允许使用)
1 | $ sudo firewall-cmd --list-ports |

开放 22222 端口
1 | $ sudo firewall-cmd --add-port=22222/tcp --permanent |

重新加载
1 | $ sudo firewall-cmd --reload |
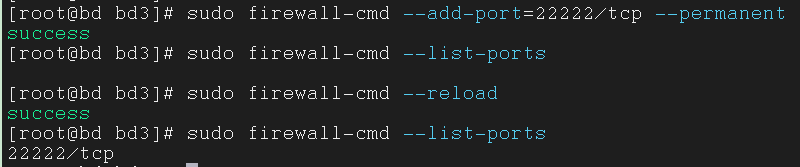
再次关闭防火墙,方便日后学习
1 | $ sudo systemctl stop firewalld |
使用 Linux 指令作为数据源
exec source:
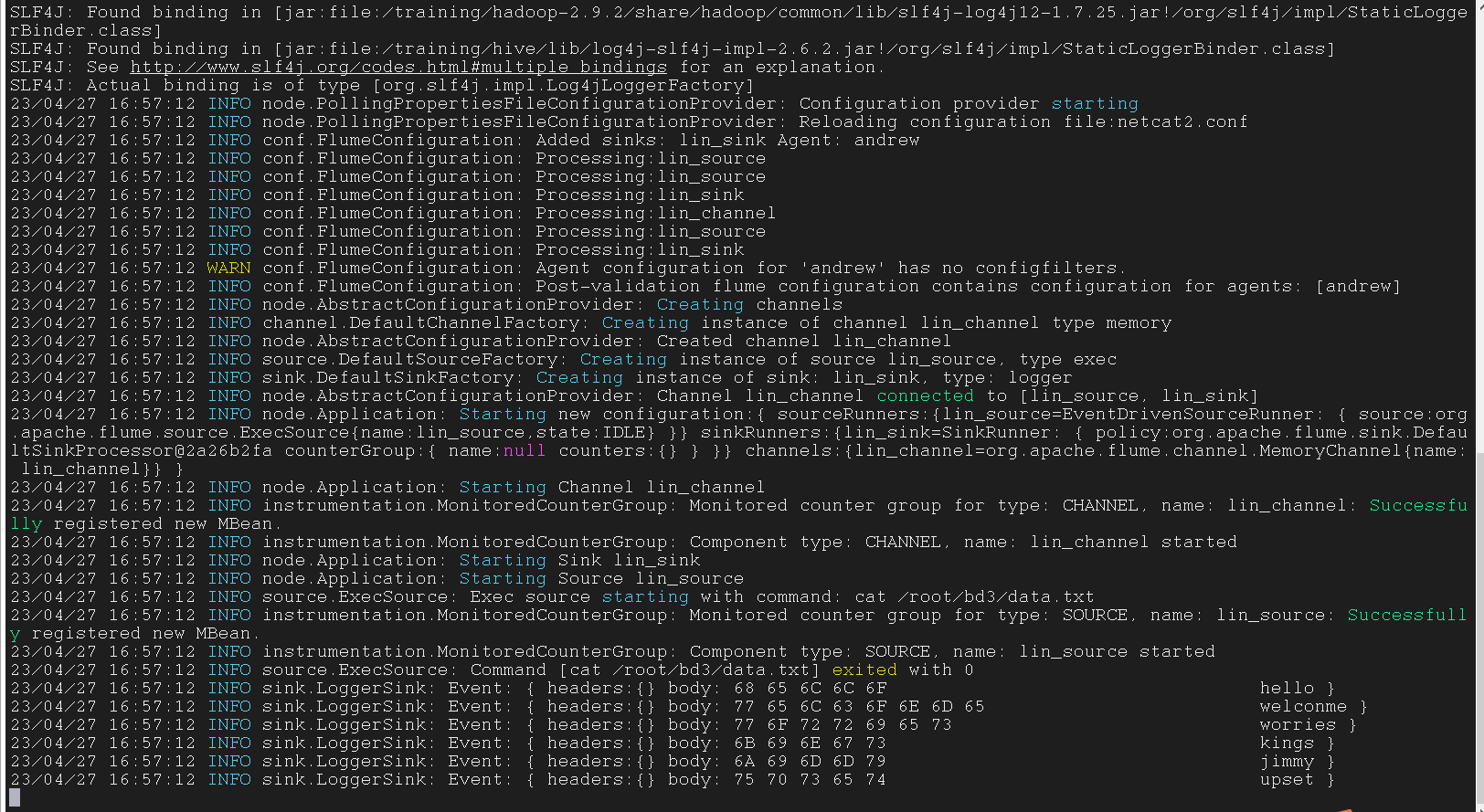
我们使用Linux指令来收集数据(Linux指令作为源代码)
通过命令产生数据,flume 会监听这个产生的数据
cat
我们修改这个文件,cat 不会更新,只能重新使用这个命令来显示
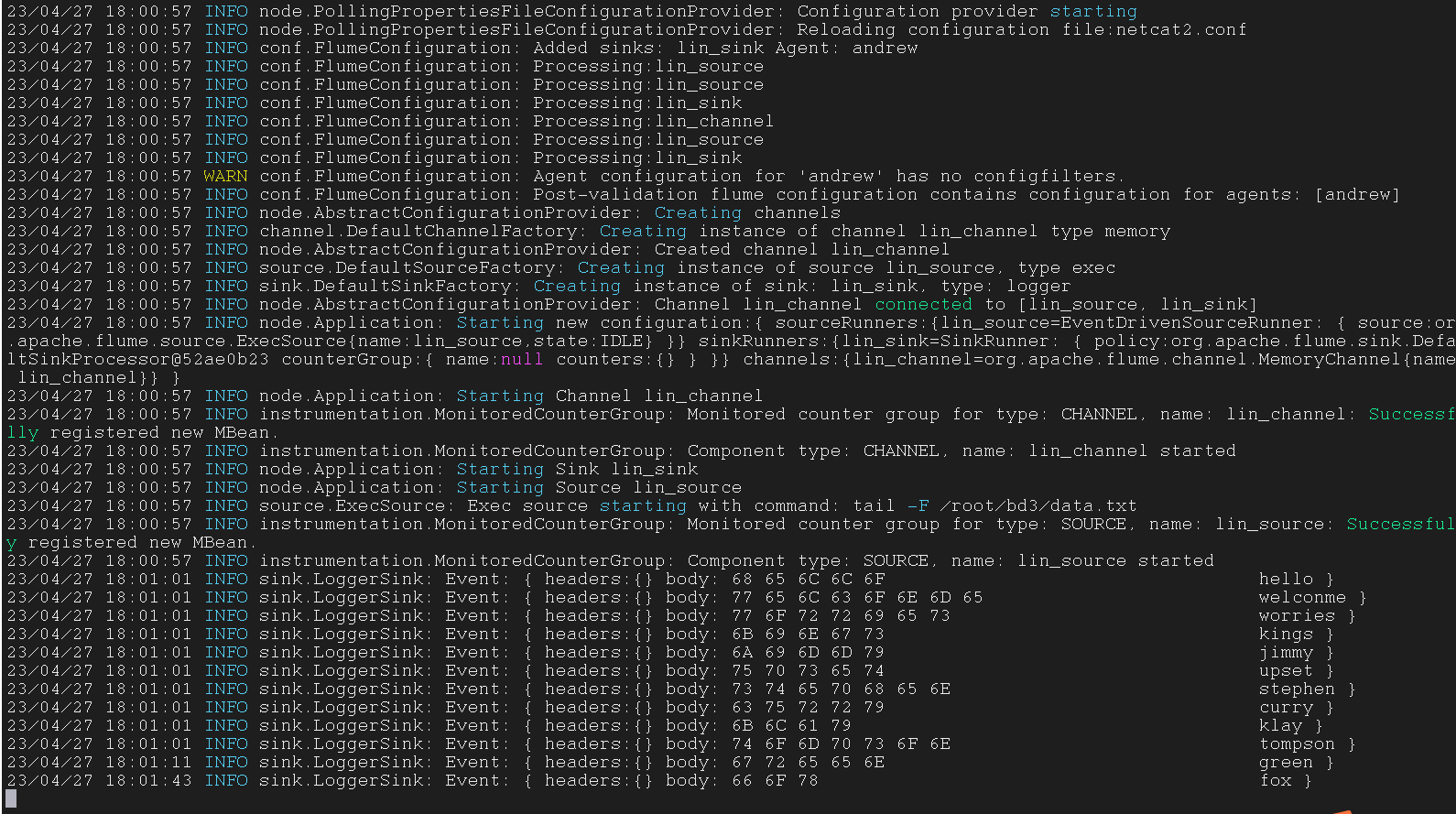
tail
tail -F
会追踪这个文件,文件更新,这个指令的显示结果就回更新
适合用于流处理
我们的数据源是执行 -cat 命令来读取这些命令
我们的source会收集数据传输到channel然后再传输到sink,再在终端上输出数据
1 | andrew.sources=lin_source |
1 | andrew.sources=lin_source |
运行指令
1 | $ flume-ng agent -n andrew -f netcat2.conf |
使用
tail指令
1 | andrew.sources=lin_source |
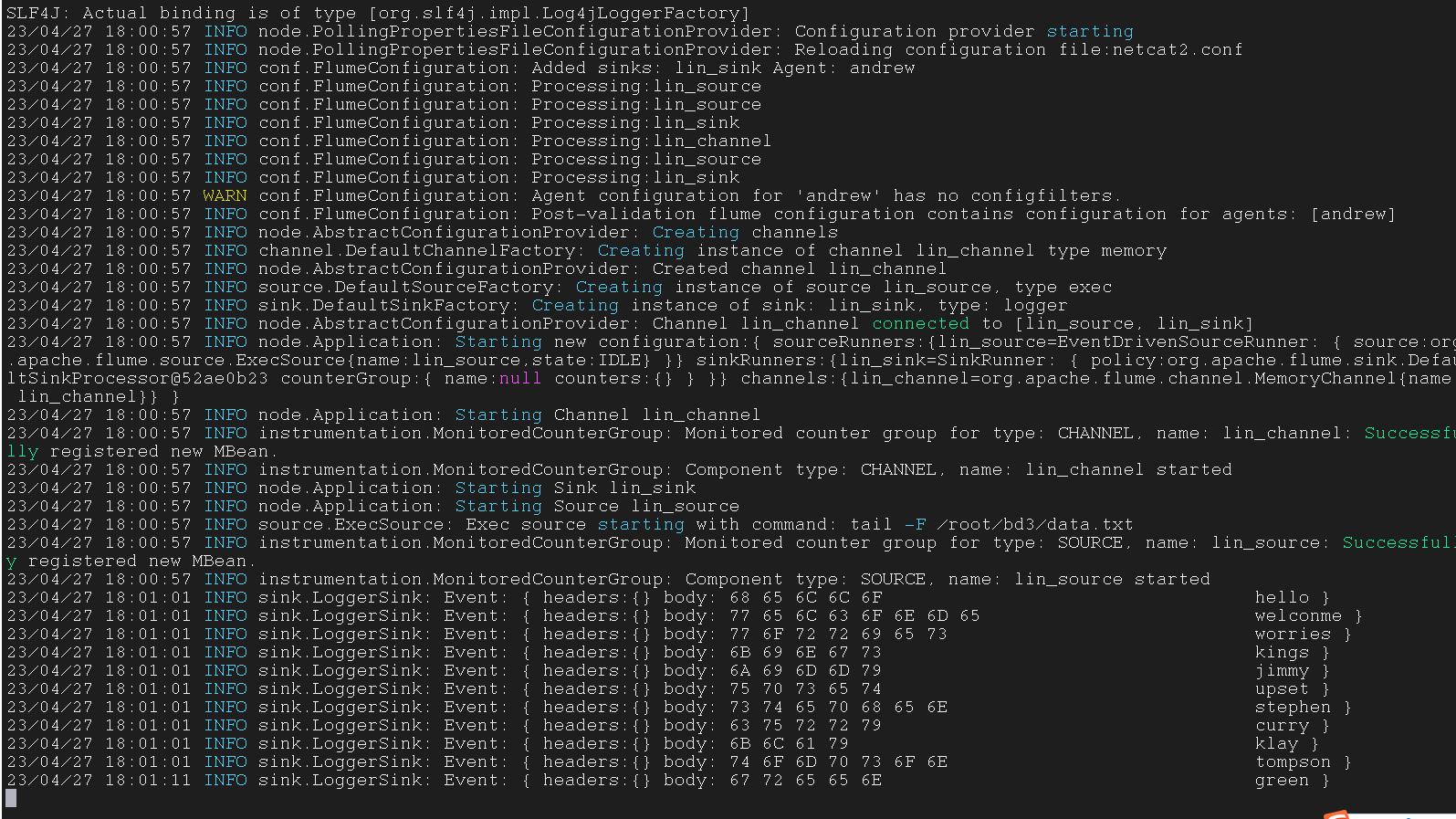
1 | $ echo "curry" >> data.txt |

更换追踪目录为
/var/log/message
这个文件是记录我们 Linux 的系统日程的
随着我们对 Linux 系统的操作,这个文件会不断更新日程
借助 tail -F 我们可以追踪更新实时数据
无论是什么系统级的操作,它都会记录下来,我们都会实时读取到
1 | andrew.sources=lin_source |
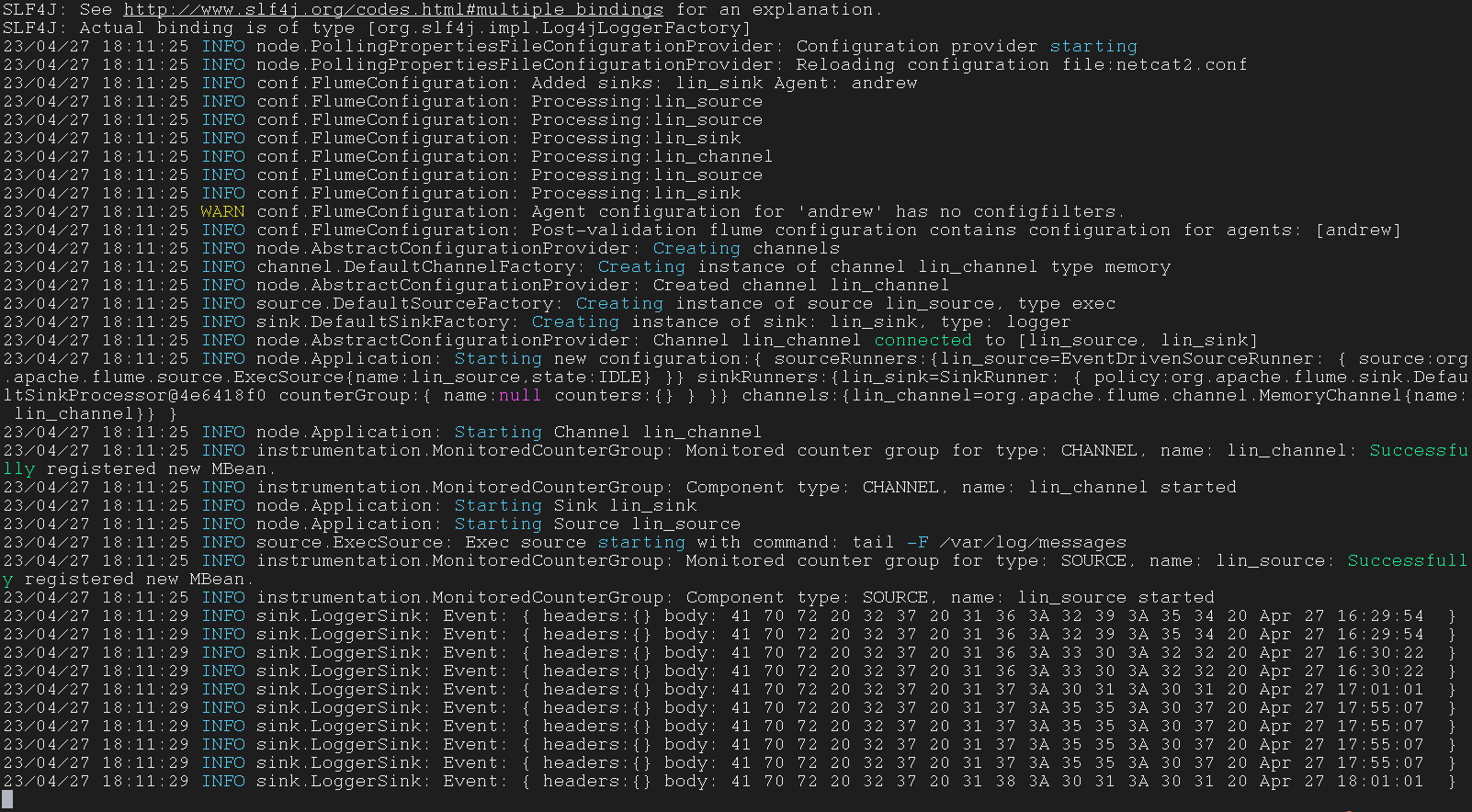
使用一整个文件夹作为数据源
1 | andrew.sources = fireworm_source |
1 | andrew.sources = fireworm_source |
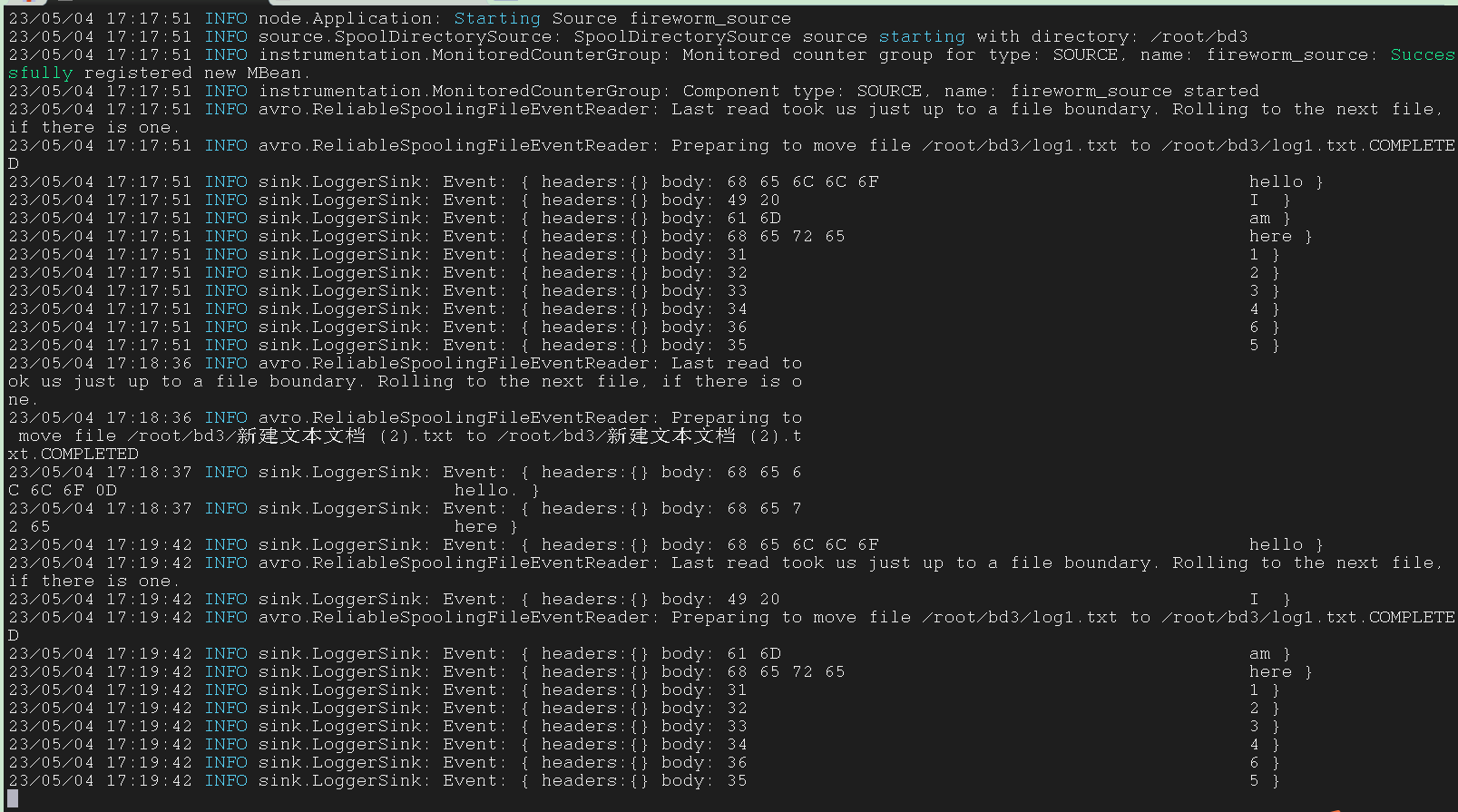
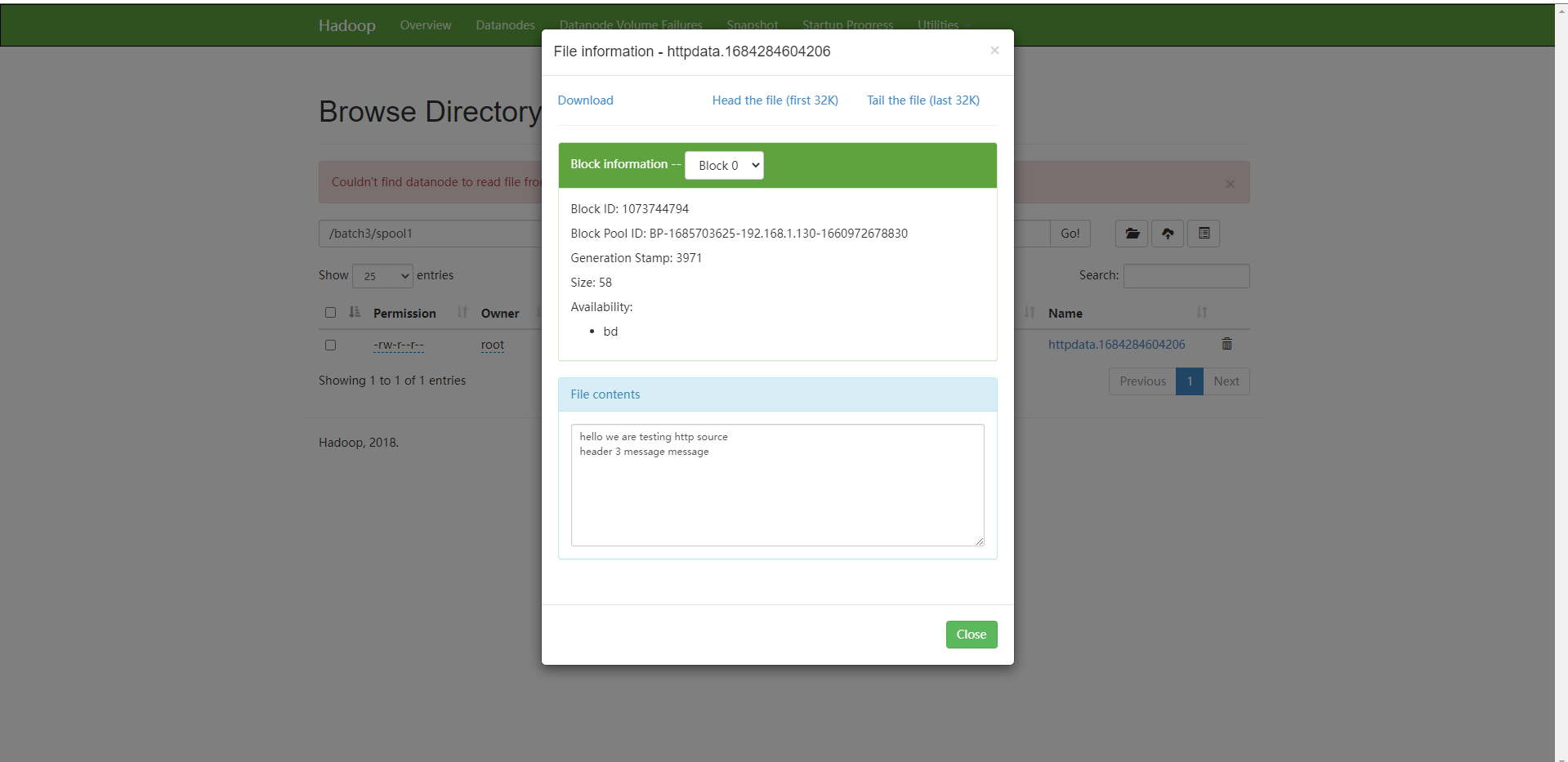
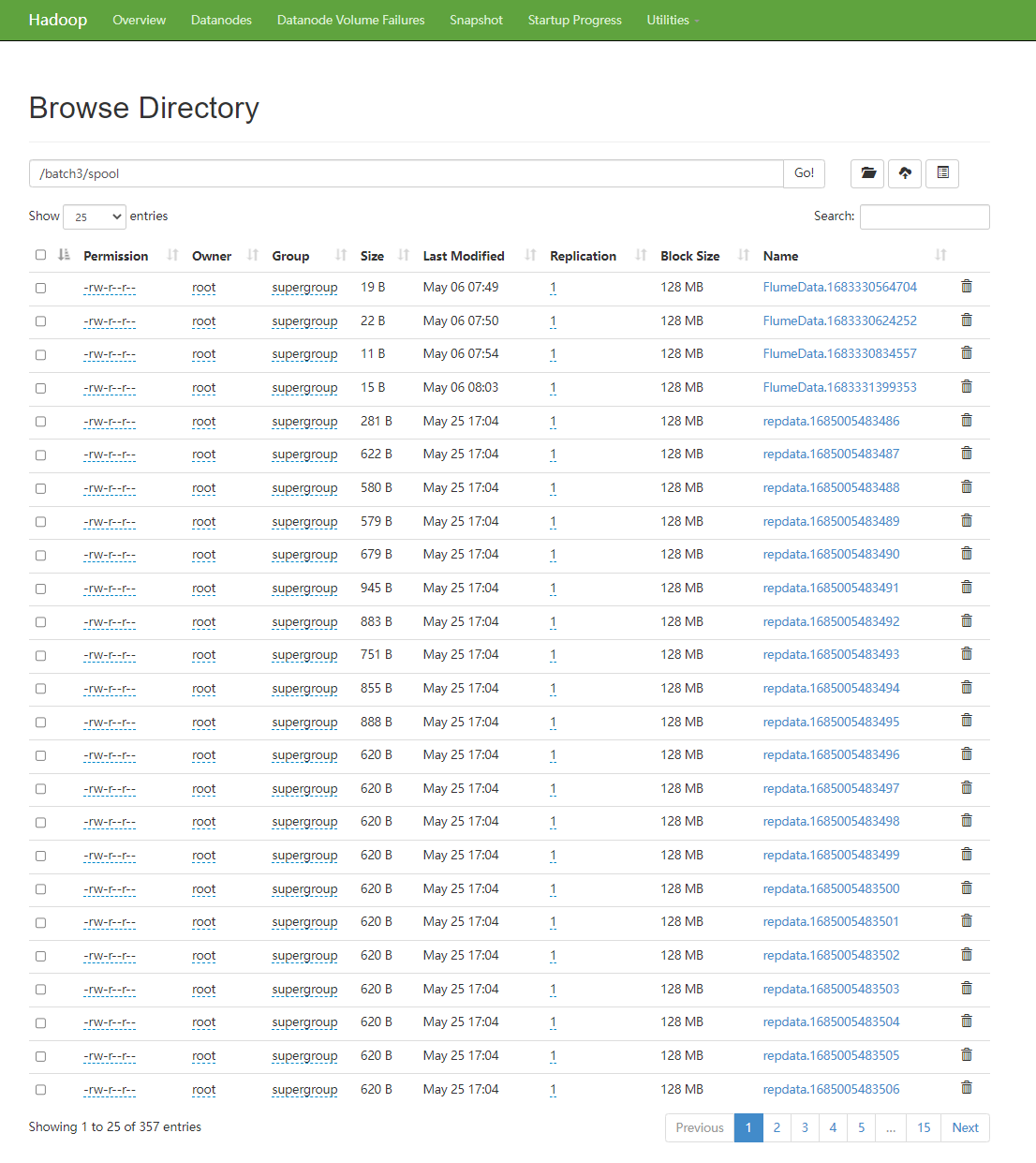
Flume 的一个文件被传输之后会被加上 .COMPLETED 标识,Flume 之后就不会传输有这个标识的文件
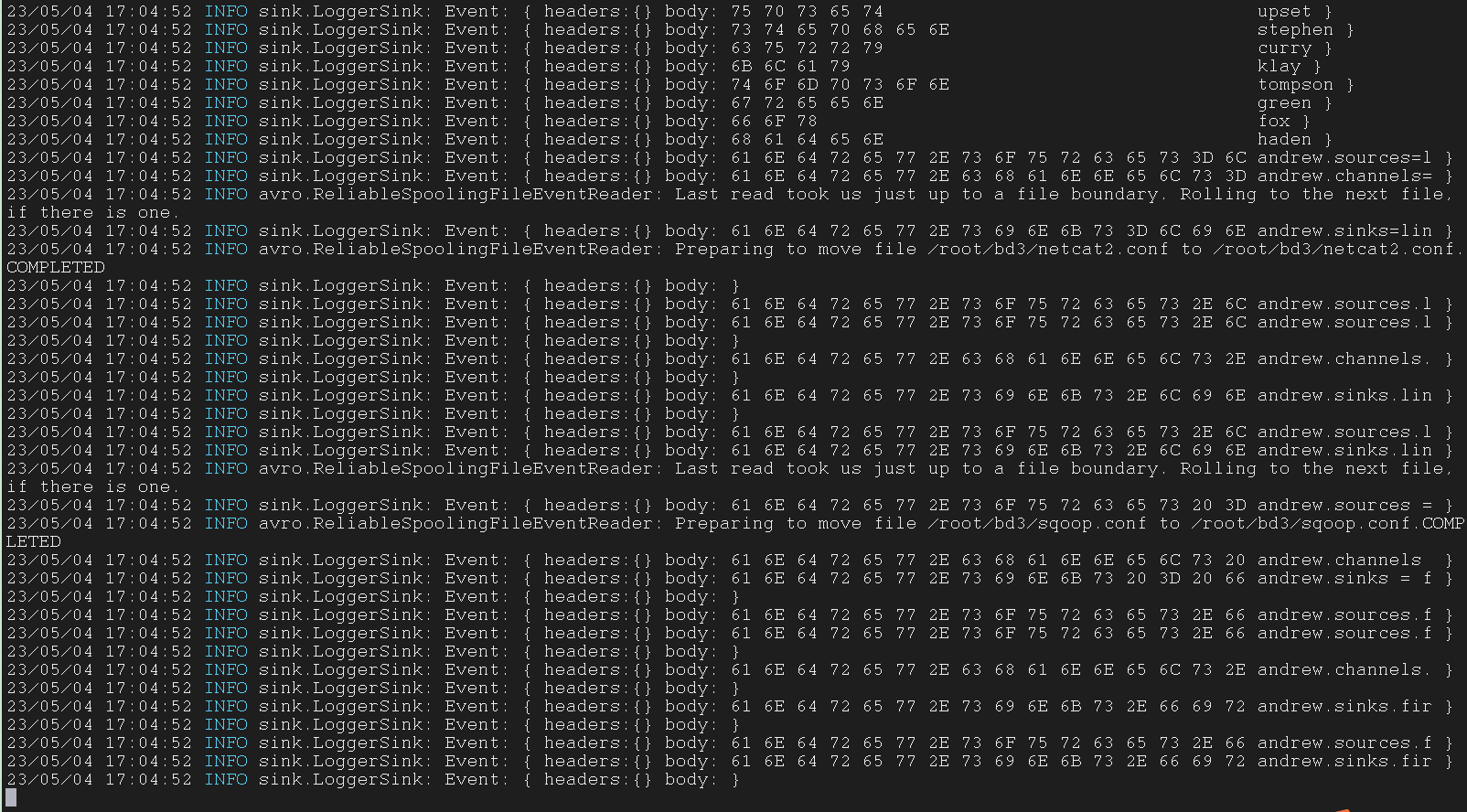

配置文件被重命名之后,文件就会被重命名,下次用它运行 Flume 的时候要用新的、被重命名之后的、后缀为 .COMPLETED 的文件
只要我们不退出程序,flume就回一直监听这个文件夹,只要有新的文件就回继续传输,不需要重启flume


如果我们手动删除了这个标识,这个文件会被当成新文件重新传输

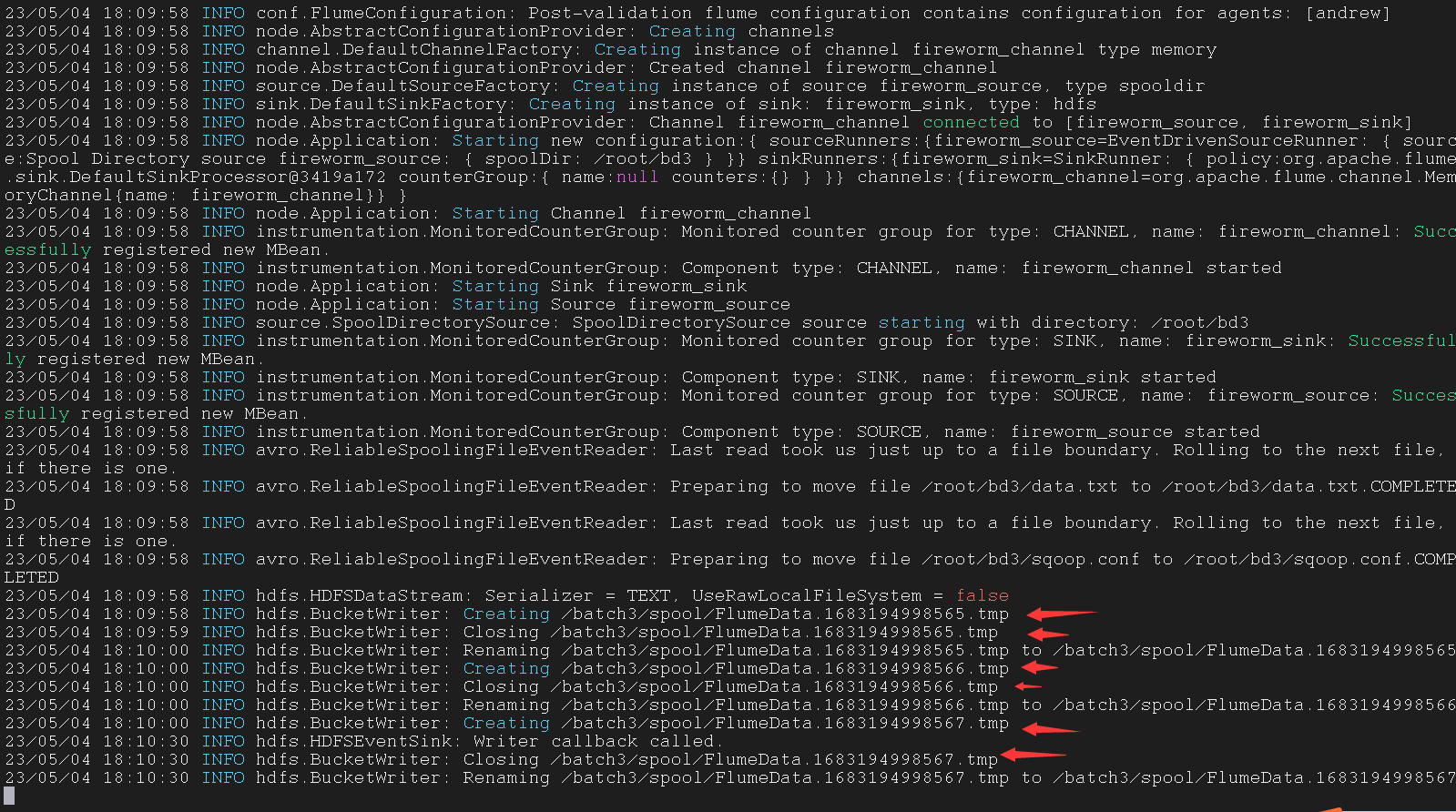
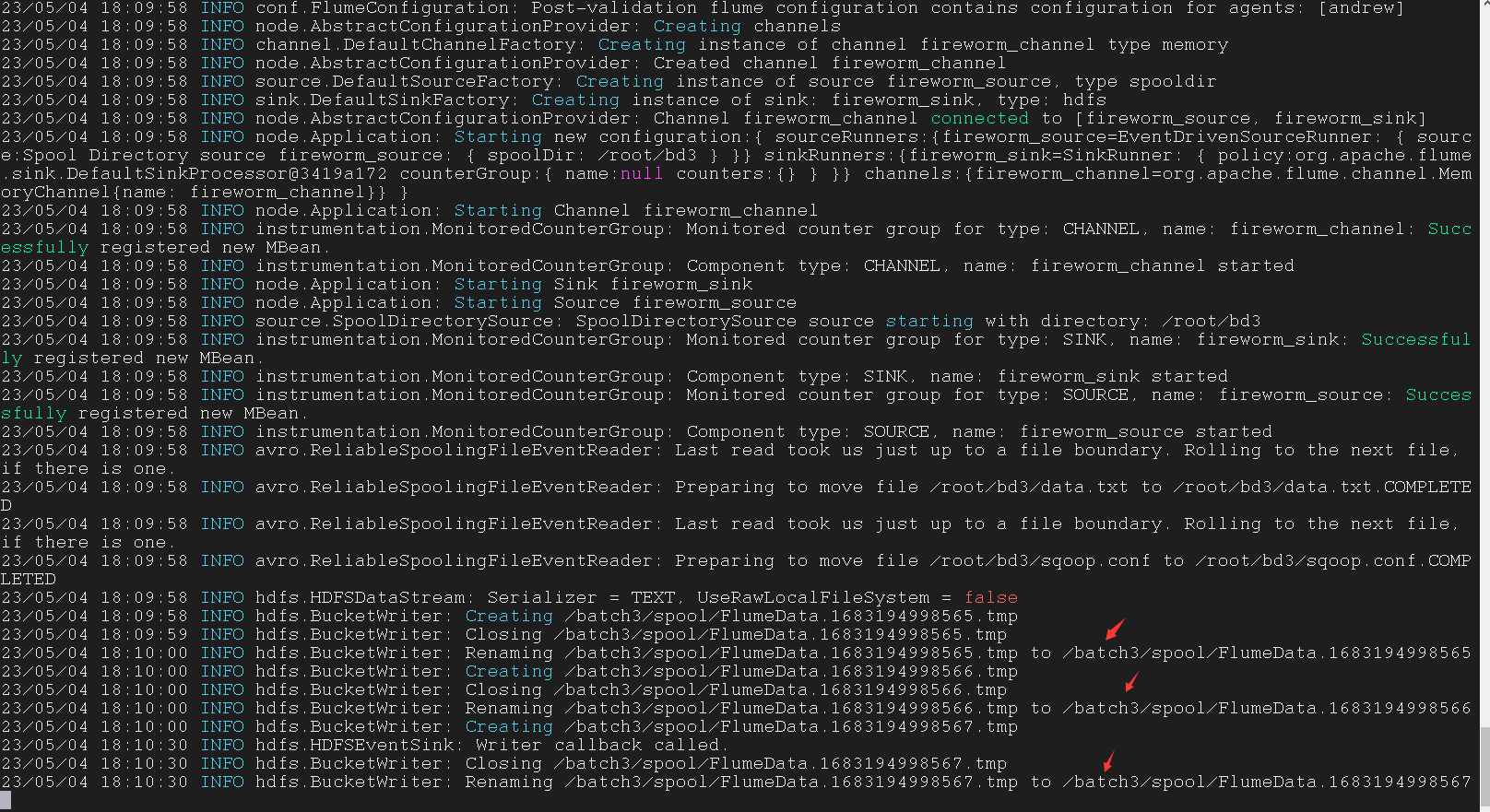
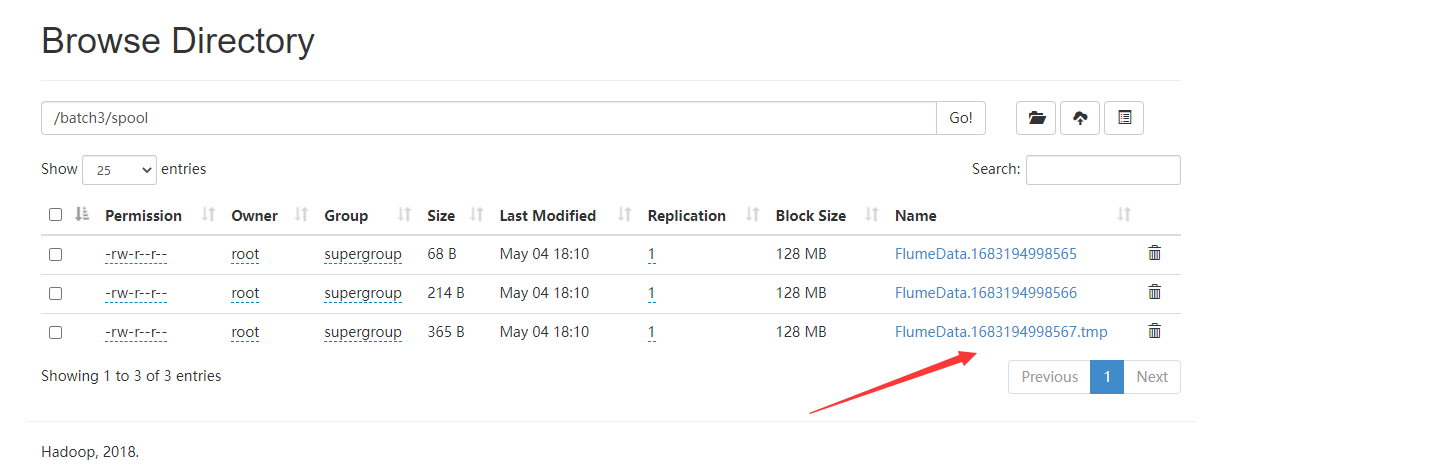
修改 sink
得先启动 Hadoop
这里也是可以监听文件夹的
1 | andrew.sources = fireworm_source |
1 | andrew.sources = fireworm_source |
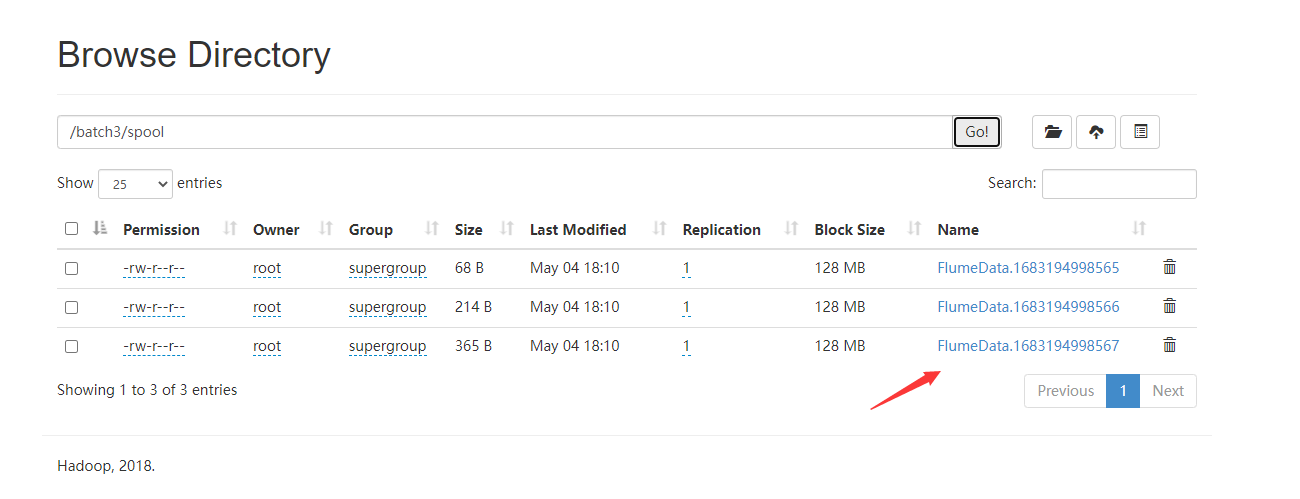
如果文件夹里有同名的文件,会报错
现在我们假设有一个 log1.txt 文件,我们在这个文件夹中使用 Flume 监听后,这个文件的文件名变成了 log1.txt.COMPLETED
现在我们尝试将另一个 log1.txt 文件从根目录中移动到这个目录下,移动过程是不会报错的
因为一个文件是 log1.txt 另一个文件是 log1.txt.COMPLETED
但是此时 Flume 监听程序会报错,因为它给这个新文件 log1.txt 加上传输标识之后,一个目录下的文件会出现重名,此时不会进行数据传输,也不会将文件改名
这时将已经有标识的 log1.txt.COMPLETED 文件删除,依然不会将新文件 log1.txt 传输,必须重新运行 Flume

使用
exec作为数据源
1 | andrew.sources = lin_source |

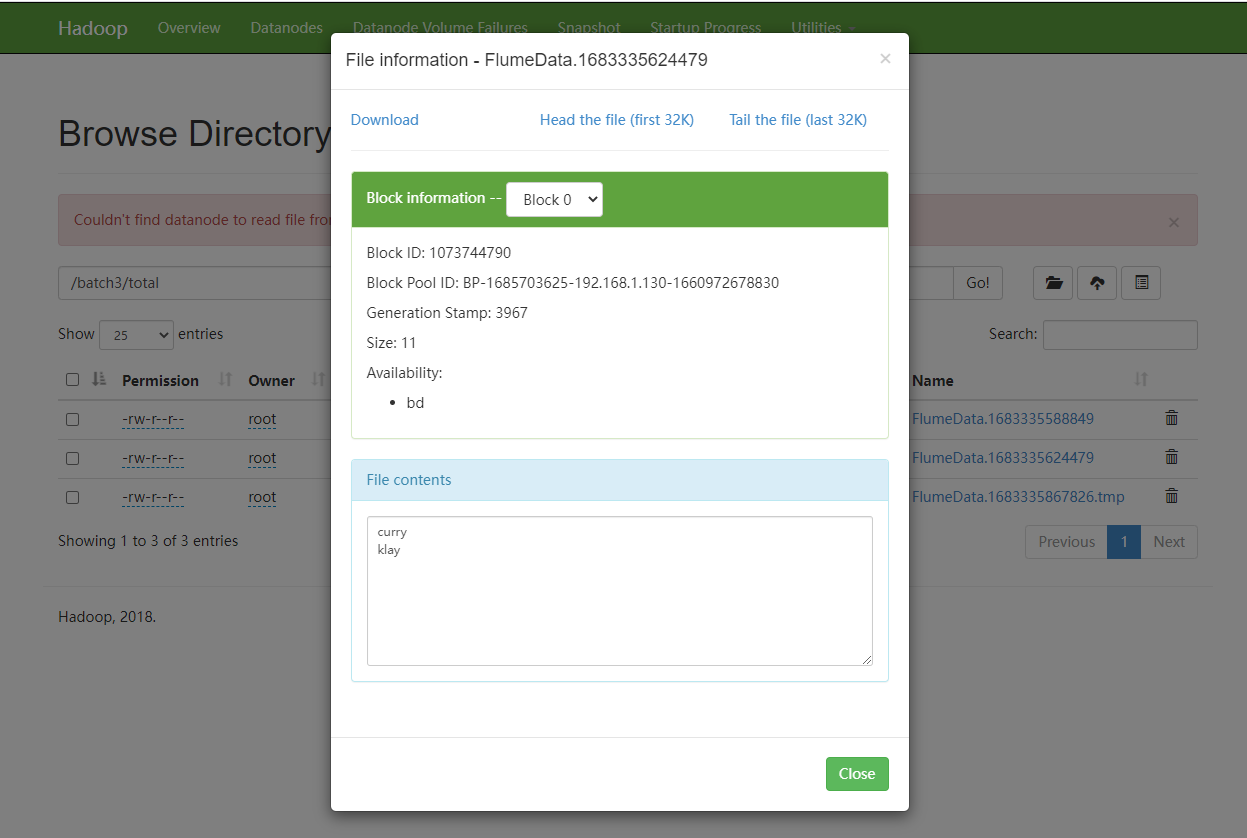
使用
netcat作为数据源
1 | andrew.sources = win_source |
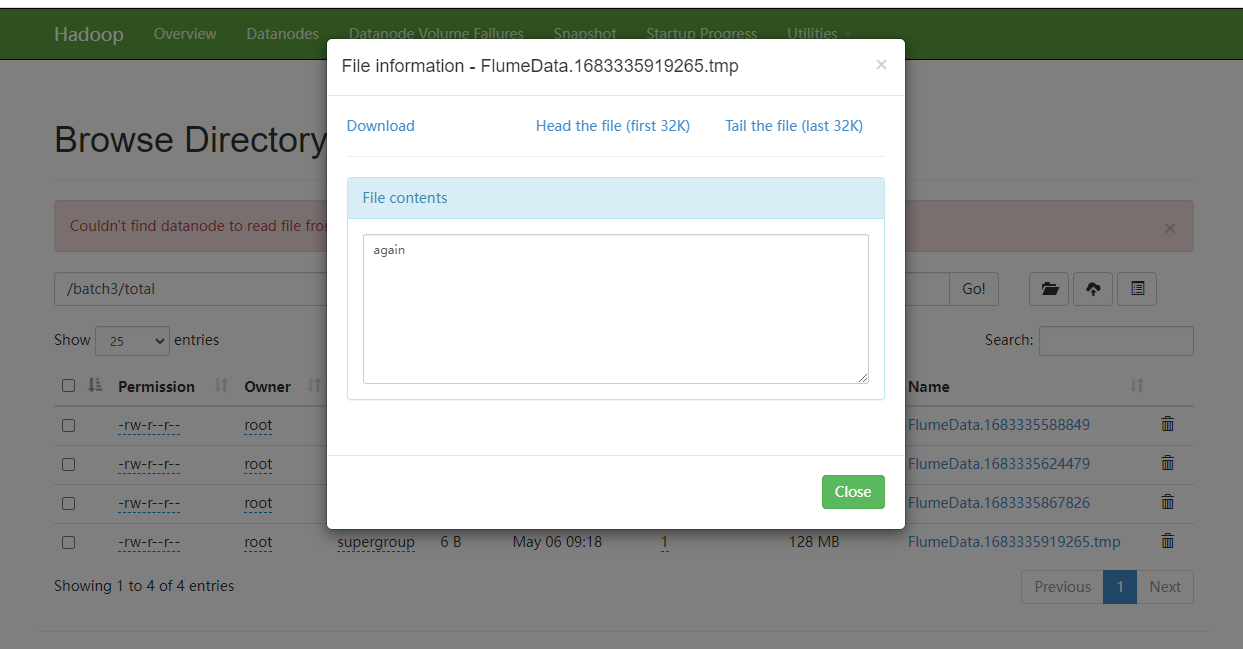
tailDir 使用文件,可以指定一个文件夹下的文件,一直传输一直上传
taildir 不会重复传输一个文件
有一个Jason文件会存储我们发送的数据和位置
要么删除文件要么修改JSON文件,否则不能重复发送文件
1 | $ ls -a |
1 | $ cd .flume |
JSON文件在这个文件夹下
taildir和spoodir //使用taildir时必须全部大写表示
ipoodir有一些限制,比如当文件传输完成后,文件后缀会变成,completed,此时当你再向这个文件中写入新数据时,fume并不会将这些新数据传输poodir: 我们可以多个文件,只要文件在我们要进行传输的路径中,flume就会全部进行传输aildir:我们可以针对特定的文件,而且它不会传输重复的内容,而且当心内容呗增加到我们传输的文件中时,它也会同步更新
gentname.sources.sourcename.tvpe=TAILDIRagentname.sources.sourcename.filegroups=f1//你想要传输多少个文件,想要一个就f1,想要两个就f2aqentname.sources.sourcename.filegroups.f1= //文件路径positionFile= //因为taildir会把传输的文件位置储存在-个ison 文件中,这就是规定这个json文件的位置
如果你要传输多个名字近似的文件,比og1.,og2.,你可以后面写”og或者说你没有这个文件,你在echo的时候添加了新文件,你也可以用这个,但是新文件必须也得是差不多这样子
HTTP Source
post 和 get 是两个方法,可以用来接收 flume 请求
.type =
.bind = 产生数据的 IP 地址
.port = 1-65535
1 | andrew.sources = win_source |
1 | andrew.sources = win_source |
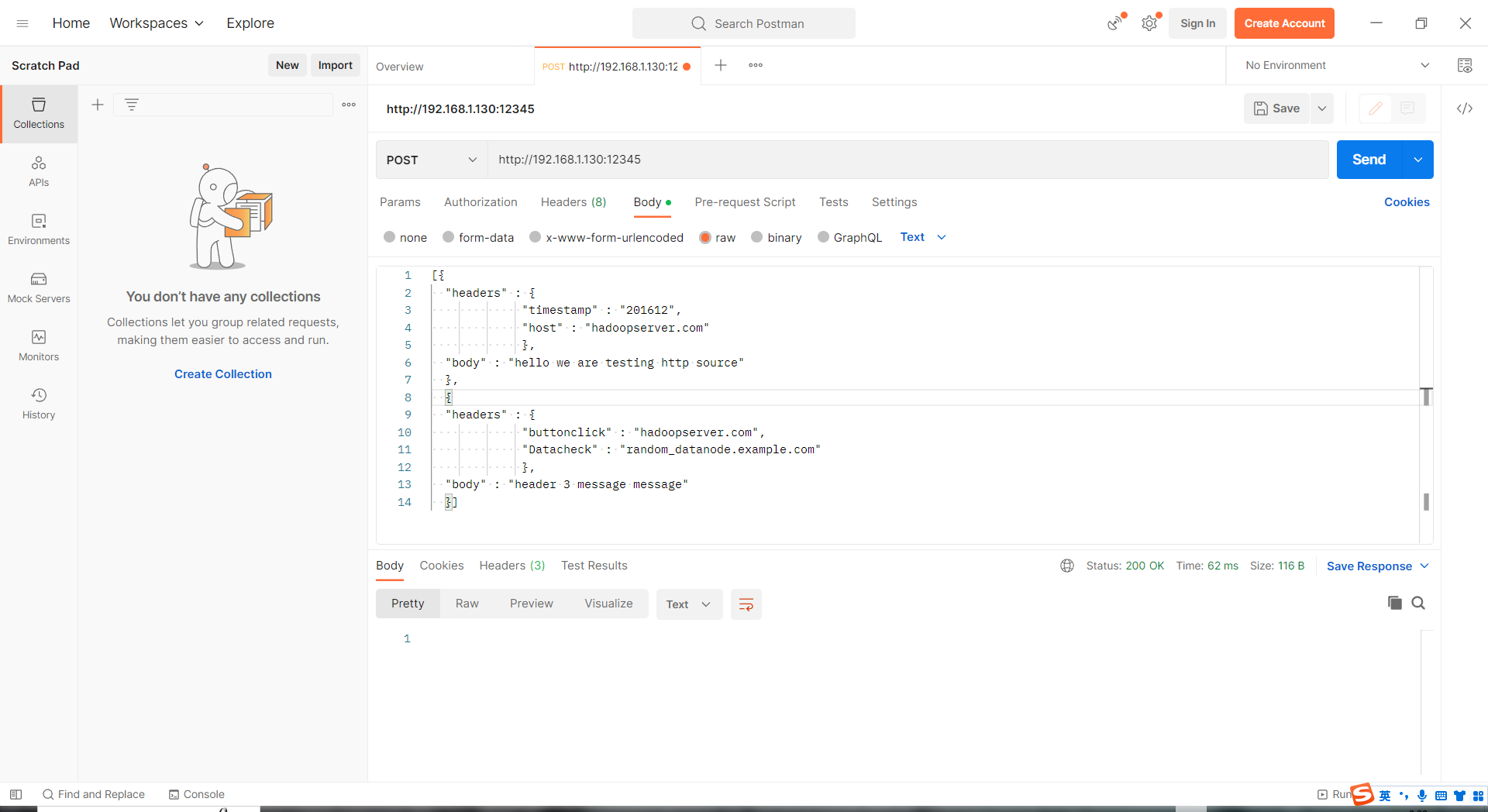
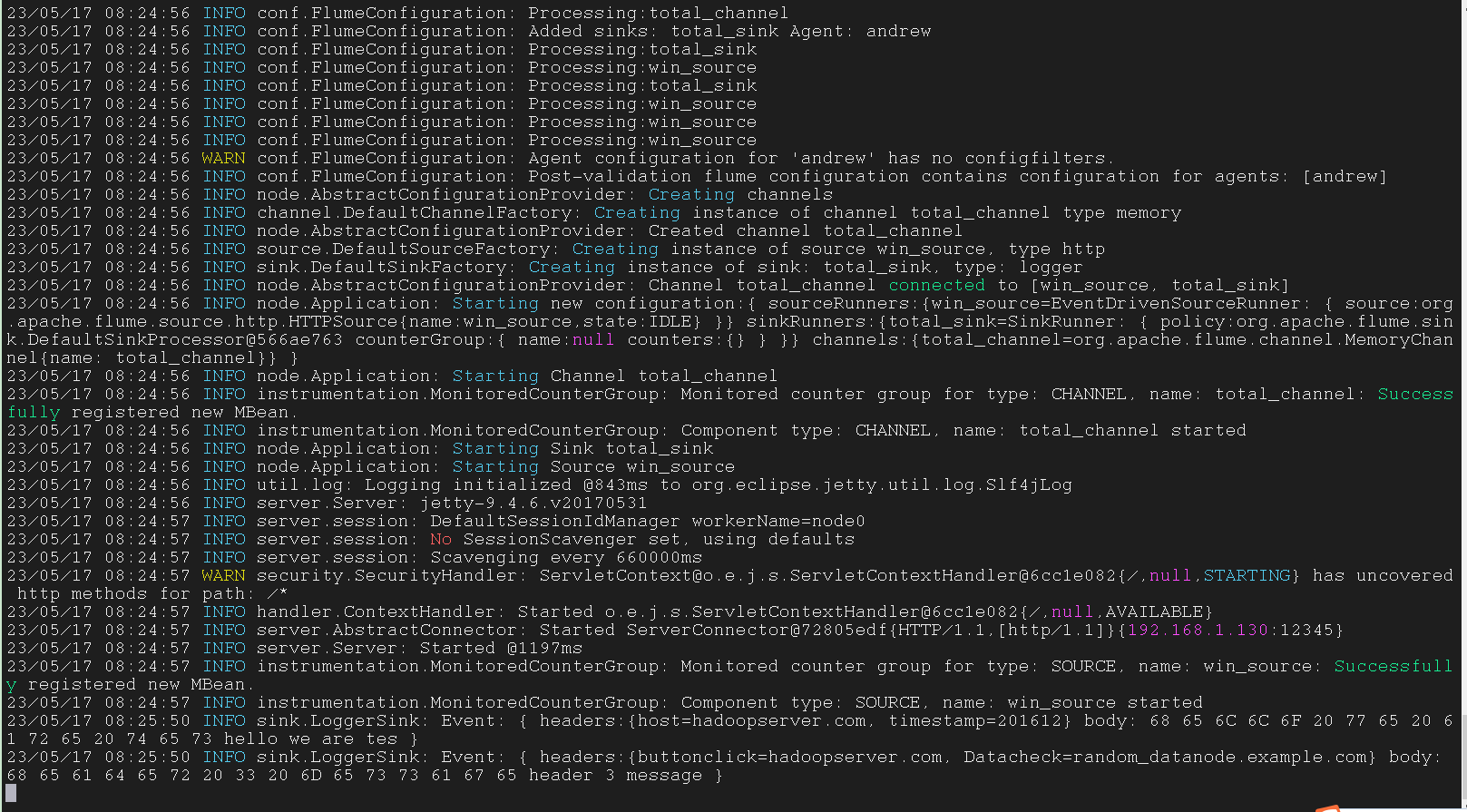
1 | andrew.sources = win_source |
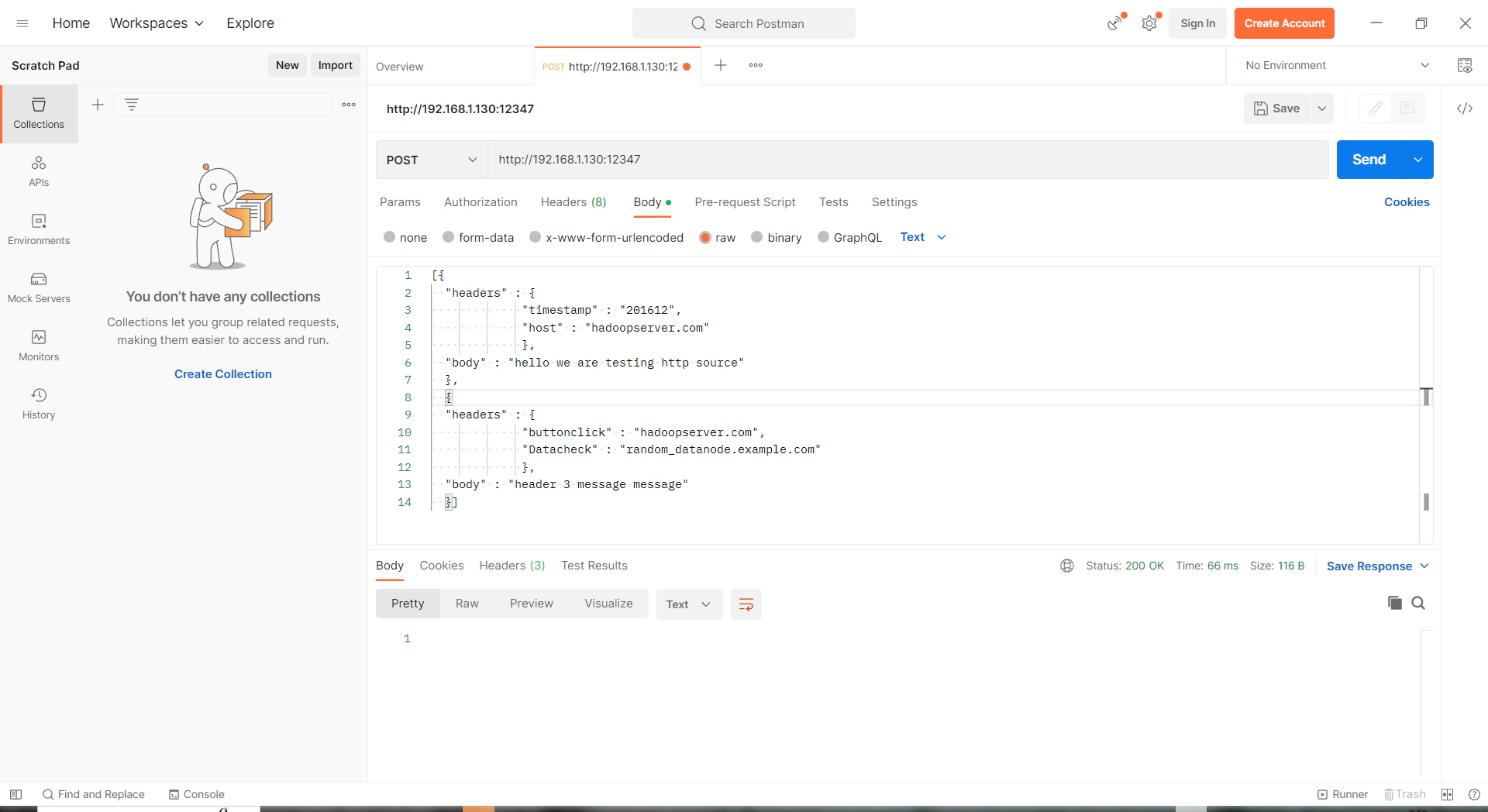
channels
capacity = 100 (默认 100) 存储容量
transactionCapacity = 100 传输容量
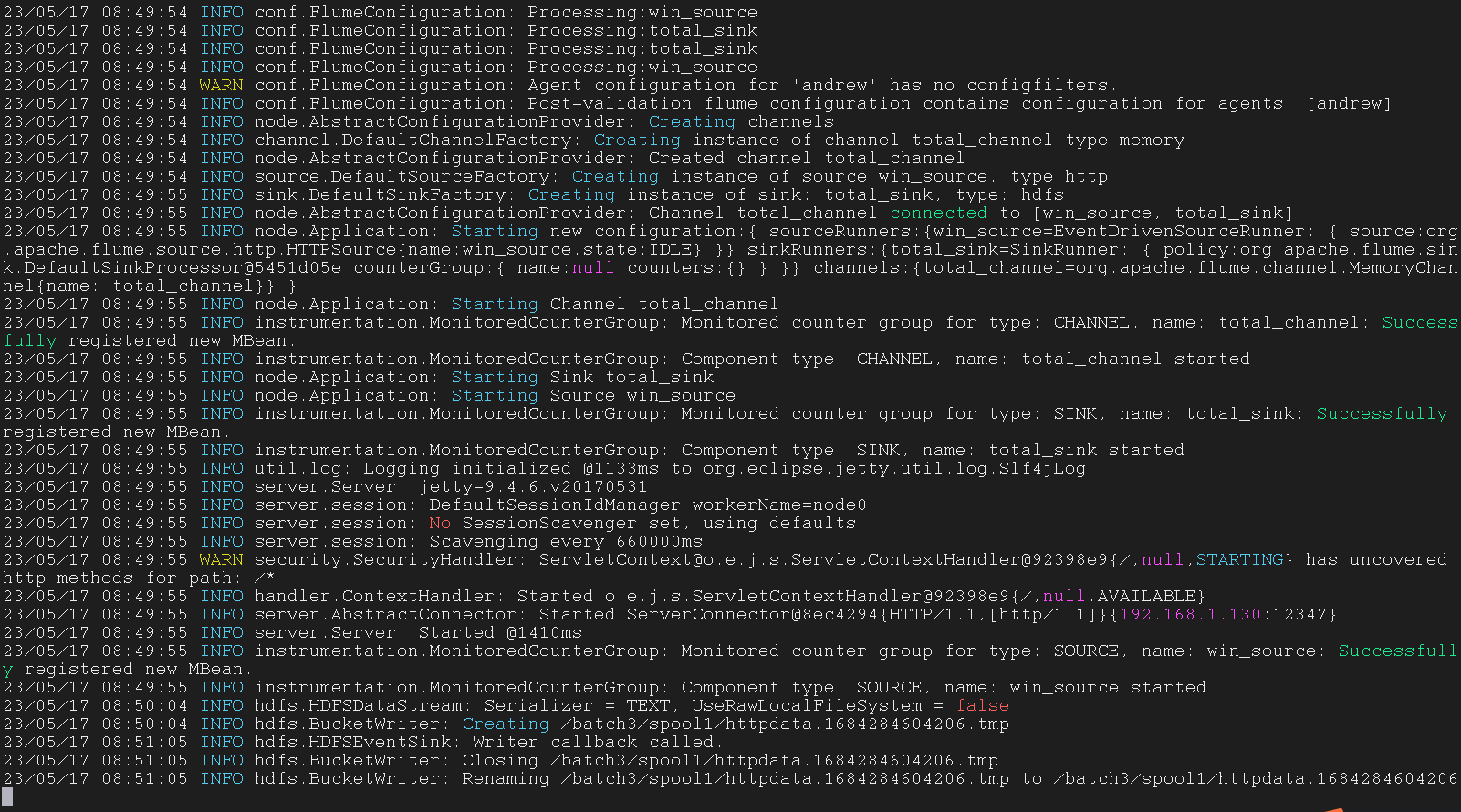
Hbase
sinks.sink1.type = hbase2
使用HBASE进行数据存储
sinks.sink1.table =
sinks.sink1.columnFamily
1 | $ start-hbase.sh |
1 | $ hbase shell |
1 | andrew.sources = hbase_source |
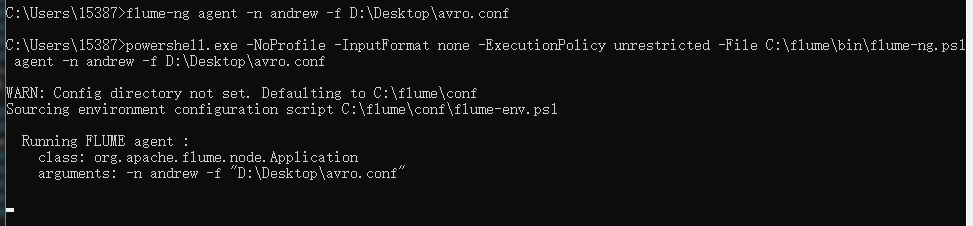
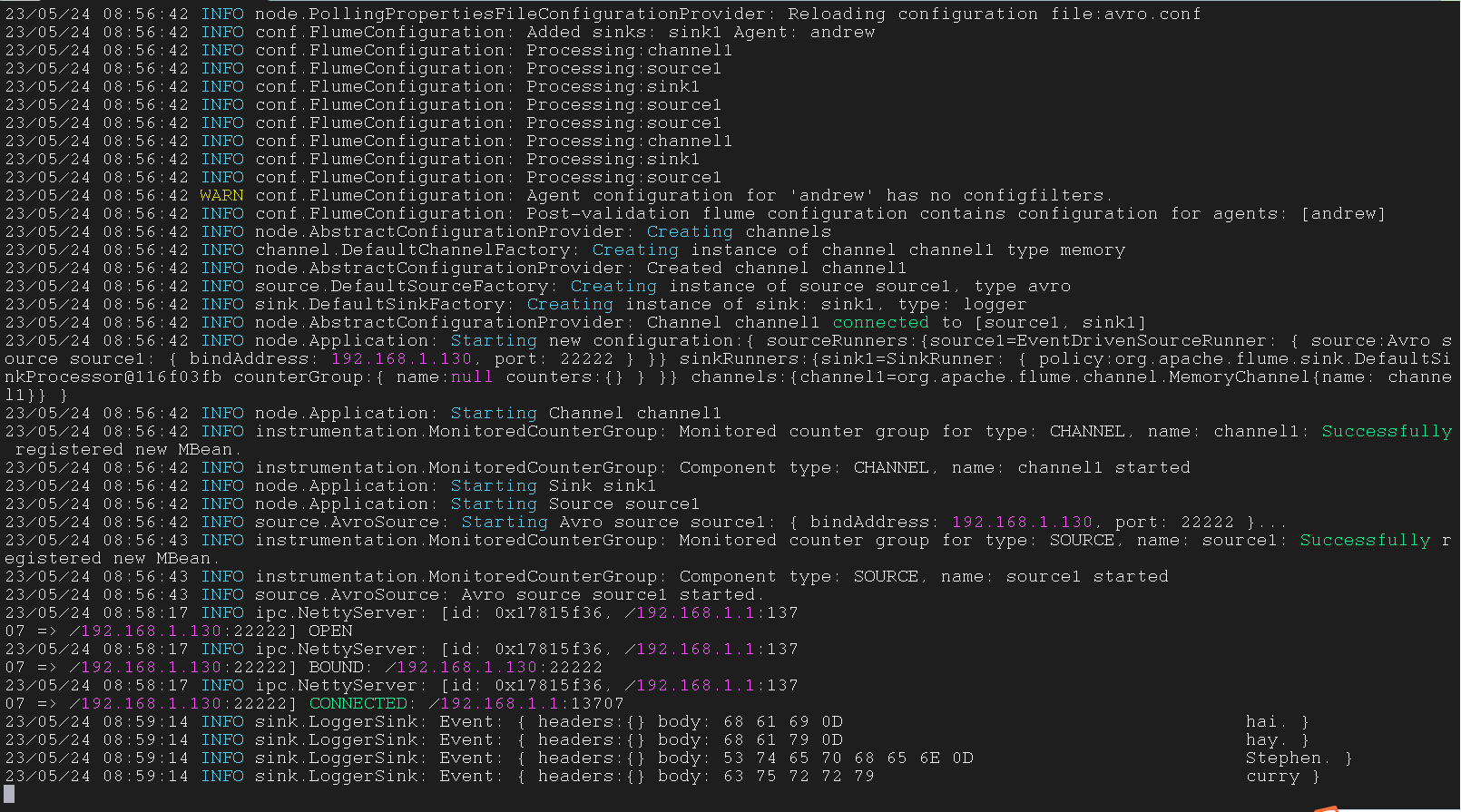
将 win 中 flume 输出的数据作为 lin 下 flume 的输入
Windows
1 | andrew.sources = source1 |
Linux
1 | andrew.sources = source1 |
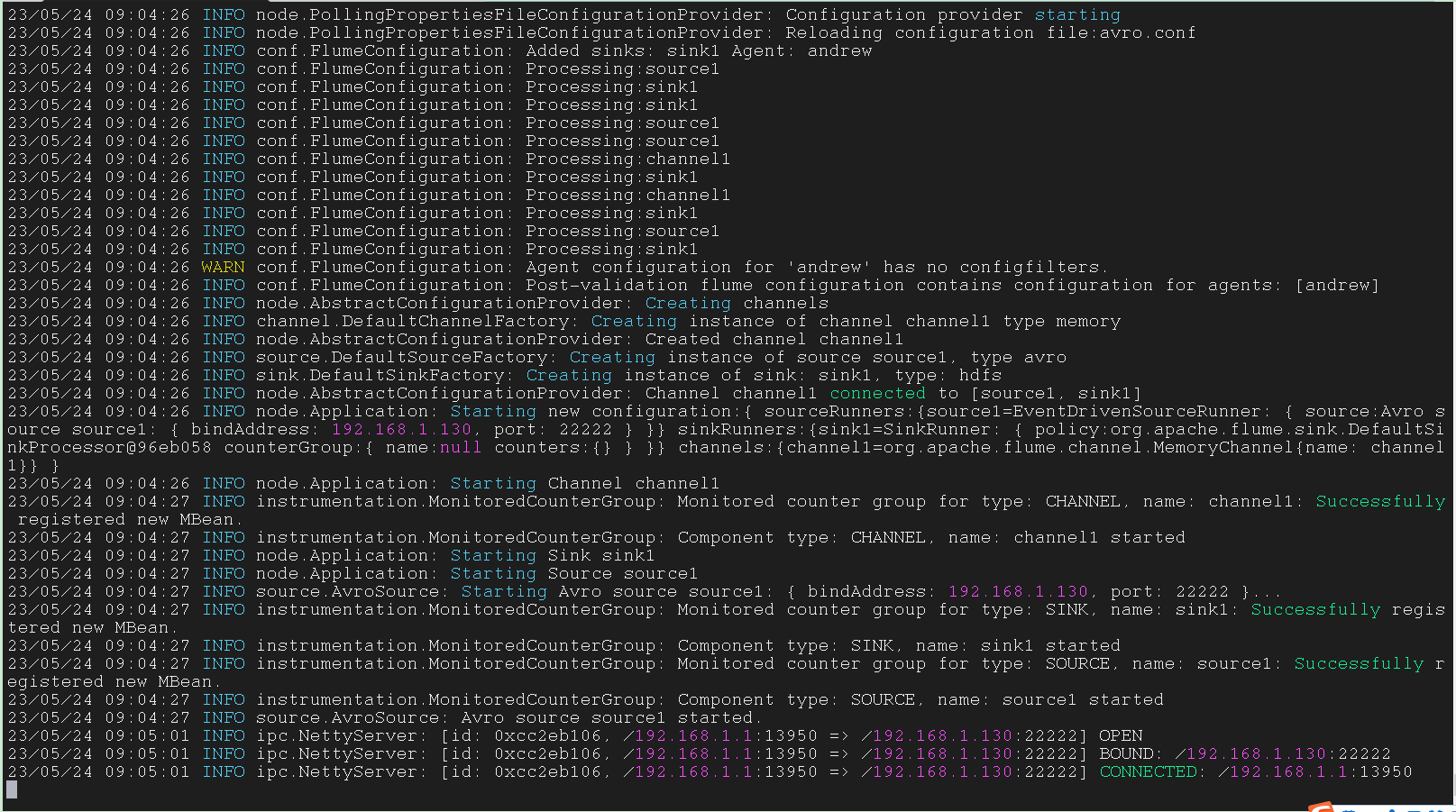
将
sink修改为 ``hdfs`
1 | andrew.sources = source1 |
多路复用扇出
传输同一个数据到两个不同的位置
1 | andrew.sources = source1 |
 wechat
wechat alipay
alipay




